
温馨提示:
本文最后更新于
2023-2-11,已超过半年没有更新,若内容或图片失效,请留言反馈。
切片(Slice) - 定义说明
在 Golang 中切片是一个 引用类型,在 进行传递时, 遵守引用传递机制。这种数据结构更 便于使用和管理数据集合。
切片是围绕 动态数组 的概念构建的, 可以 按需自动增长和缩小。切片的动态增长是通过内置函数append()来实现的, 这个函数可以快速且高效地增长切片(容量自动以切片长度的倍数扩容), 也可以通过对切片再次切割, 缩小一个切片的大小。
因为切片的底层也是在连续的内存块中分配的, 所以 切片还能获得索引、迭代以及为垃圾回收优化的好处。切片的使用和数组类似, 遍历切片、访问切片的元素和求切片的长度len()都一样。
我简单描述下切片的使用姿势和演示说明
package main
import (
"fmt"
)
func main() {
// 声明/定义 var slice []int
var intArr [5]int = [...]int{1, 2, 3, 4, 5}
// 定义一个切片, 让切片去引用一个已经创建好的数组, 将数组下标为1的元素到下标为3的元素(不包含3) 转为切片
slice := intArr[1:3]
fmt.Println(slice) // 输出: [2 3]
// 改变 slice 值
slice[1] = 10
fmt.Println(slice) // 输出: [2 10]
fmt.Println(intArr) // 输出: [1 2 10 4 5] (由于切片是引用类型, 所以如果切片内将这块引用内容值做修改, 将会改变 intArr 数组内容值, 下面将用内存示意图证明)
fmt.Println(reflect.TypeOf(slice).Kind()) // 数据类型为切片 slice
fmt.Println(len(slice), cap(slice)) // 大小为:2 容量为:4
// slice 底层可以理解为数据结构 struct 结构体
/*
type slice struct {
ptr *[2]int // [2]int 根据切片而变化
len int
cap int
}
*/就以上代码我这边整理成了内存布局, 看看内存结构是怎样的
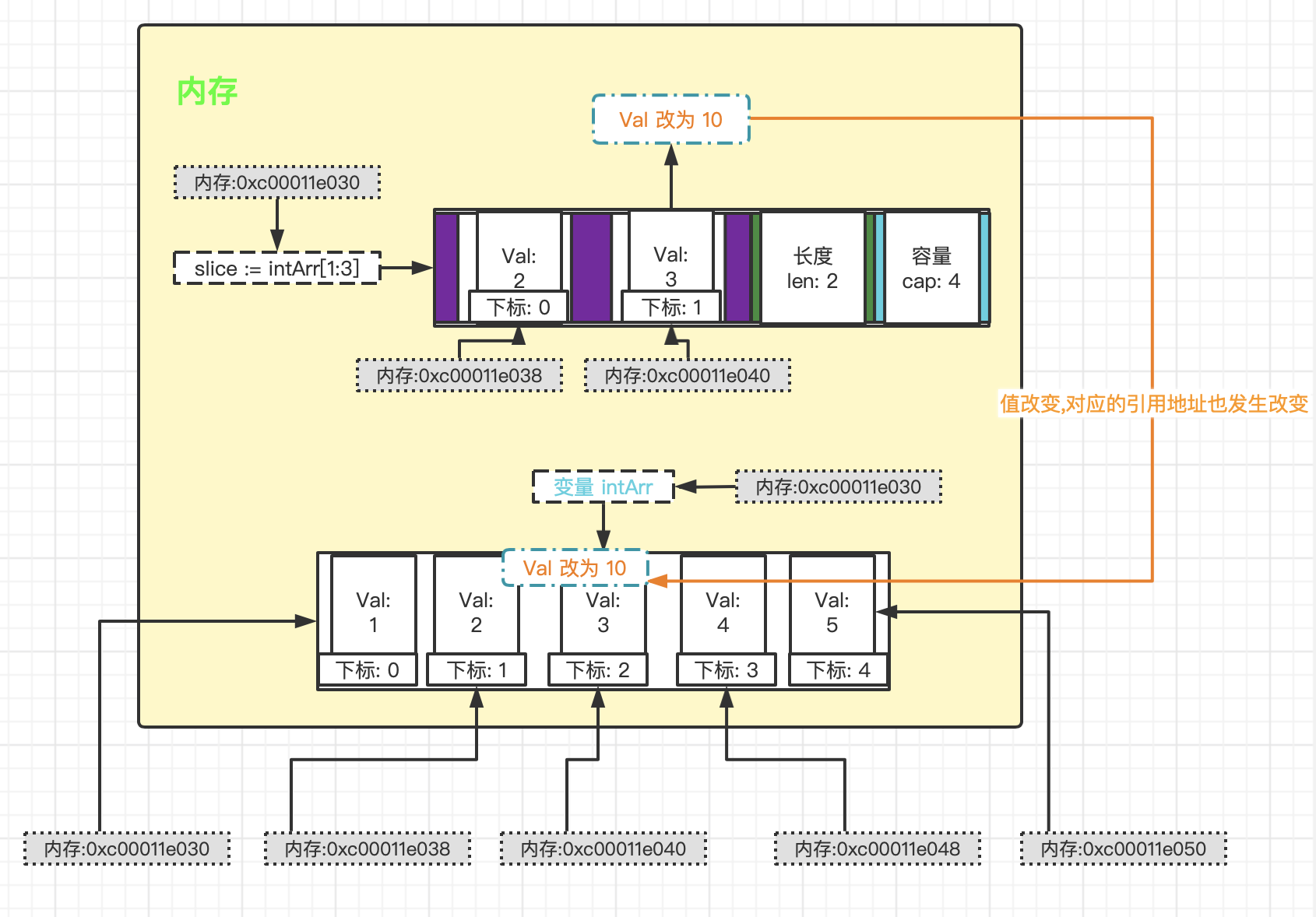
从上面的内存图我们可以看到 (切片内存规则和数组内存规则类似, 可查阅! golang 数组与内存布局, 方便以下内容的理解):
slice := intArr[1:3]基于intArr 数组变量将下标为1-2的元素创建一个新的切片。图中可以看到,slice 切片变量的两个元素内存地址其实就是对应(指向)到intArr 数组变量为下标1-2的元素,slice 切片变量下标为0和1的元素内存地址 =intArr 数组变量下标为1和2的元素内存地址 =0xc00011e038和0xc00011e040, 从而当切片这部分元素值发生变化时, 数组的值也同时发生变化(因为都是指向同个内存地址); 相反, 当数组的值发生变化, 切片的这部分元素也发生变化, 这个应该不难理解。- 切片的长度
len表示元素的数量, 而cap容量则是个 倍数扩容, 比如: 当元素数量为2的时候, 容量为4; 元素数量达到4的时候, 容量为8; 元素数量达到8的时候, 容量为16 ... 依此类推切片的声明/定义有三种方式
- 定义一个切片, 让切片去引用一个已经创建好的数组, 比如上述的案例就是这种方式
- 通过
make来创建切片, 基本语法:var 切片名(变量名) []type = make([], len, [cap])
参数说明:type: 数据类型 |len: 大小 |cap: 指定切片容量, 可选(如果分配了cap, 则要求cap >= len), 用处不大, 当切片大小达到这个容量时还是可以继续append,cap依然会发生变化- 定义一个切片, 直接指定具体数组, 使用原理类似
make方式, 例如:var slice []string = []string{"tom", "jack", "marry"}
特别说明下 make 创建切片的内存示意图
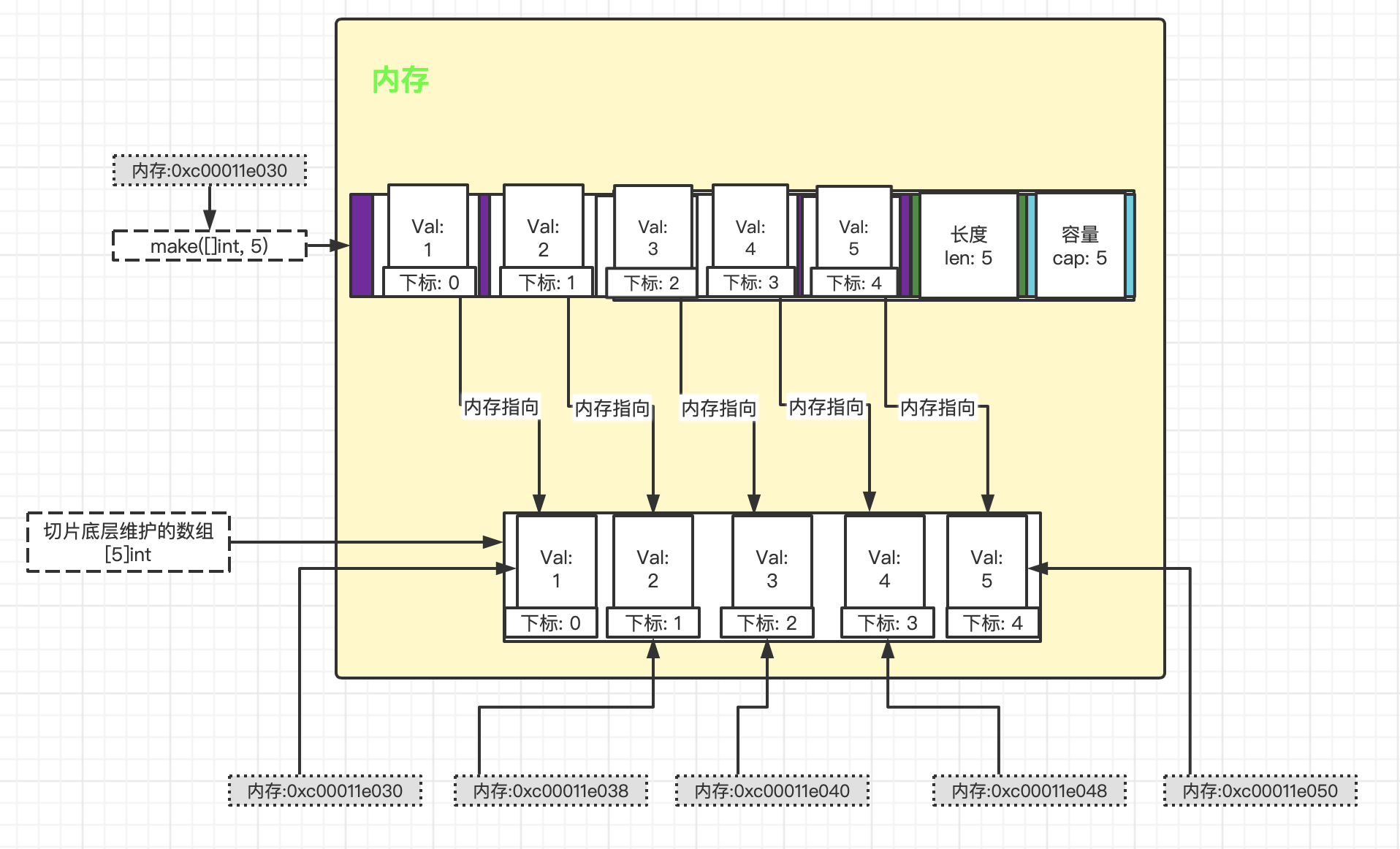
从上面的切片声明/定义来看, ·方式1· 和 ·方式2· 是有点区别的:
- 方式1 是
直接引用数组, 这个数组是事先存在的, 程序员是可见的。- 方式2 是通过
make来创建切片,make其实也会创建一个数组, 由切片在底层进行维护, 程序员是不可见的。
而使用append扩容的时候, 内存的变化也是不一样的。 因为底层是数组维护, 数组是没办法扩容的。
1) 如果是添加的已存在的切片变量, 比如:
var vnode_slice []int
vnode_slice = append(vnode_slice, 1)
var slice [][]int
slice = append(slice, vnode_slice)这种情况下, 底层会直接将内存地址同时指向 vnode_slice 变量的内存地址
2) 如果是添加新的数据扩容, 比如:
var slice []int
slice = append(slice, 1)这种情况下, 底层会新创建一个数组并计算 len和 cap, 将原本的数据拷贝到该新数组中, 然后把原本指向的内存地址改为指向新创建的数组内存地址, (GC)垃圾回收掉之前的数组。
这里就不一一画图了, 脑海中联想出来即可。
好了, 就先介绍到这。
评论一下?