-
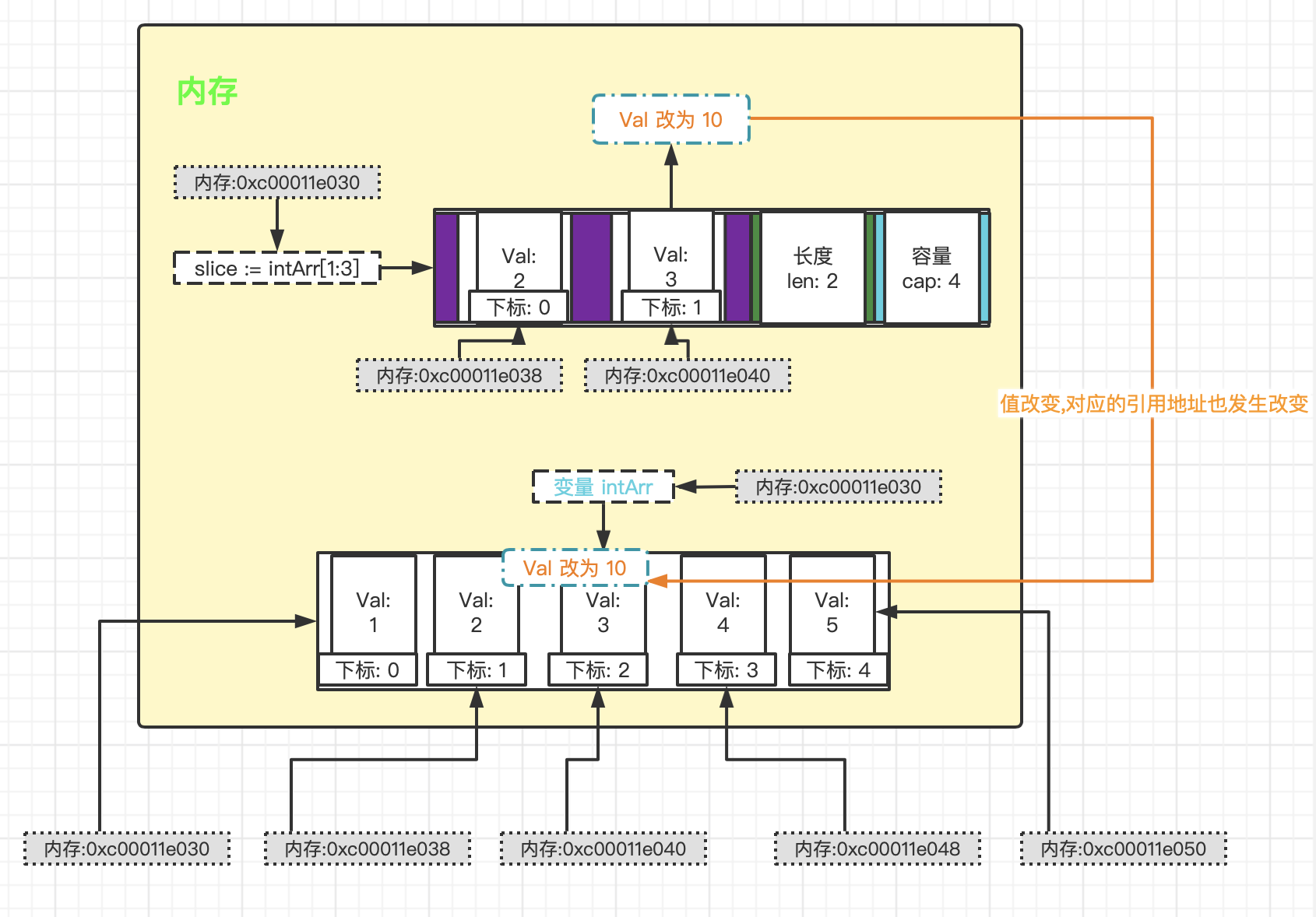 Golang 切片与内存布局 切片(Slice) - 定义说明 在 Golang 中切片是一个 引用类型,在 进行传递时, 遵守引用传递机制。这种数据结构更 便于使用和管理数据集合。 切片是围绕 动态数组 的概念构建的, 可以 按需自动增长和缩小。切片的动态增长是通过内置函数 append() 来实现的, 这个函数可以快速且高效地增长切片(容量自动以切片长度的倍数扩容), 也可以通过对切片再次切割, 缩小一个切片的大小。 因为切片的底层也是在连续的内存块中分配的, 所以 切片还能获得索引、迭代以及为垃圾回收优化的好处。切片的使用和数组类似, 遍历切片、访问切片的元素和求切片的长度 len() 都一样。 我简单描述下切片的使用姿势和演示说明 package main import ( "fmt" ) func main() { // 声明/定义 var slice []int var intArr [5]int = [...]int{1, 2, 3, 4, 5} // 定义一个切片, 让切片去引用一个已经创建好的数组, 将数组下标为1的元素到下标为3的元素(不包含3) 转为切片 slice := intArr[1:3] fmt.Println(slice) // 输出: [2 3] // 改变 slice 值 slice[1] = 10 fmt.Println(slice) // 输出: [2 10] fmt.Println(intArr) // 输出: [1 2 10 4 5] (由于切片是引用类型, 所以如果切片内将这块引用内容值做修改, 将会改变 intArr 数组内容值, 下面将用内存示意图证明) fmt.Println(reflect.TypeOf(slice).Kind()) // 数据类型为切片 slice fmt.Println(len(slice), cap(slice)) // 大小为:2 容量为:4 // slice 底层可以理解为数据结构 struct 结构体 /* type slice struct { ptr *[2]int // [2]int 根据切片而变化 len int cap int } */ 就以上代码我这边整理成了内存布局, 看看内存结构是怎样的 从上面的内存图我们可以看到 (切片内存规则和数组内存规则类似, 可查阅! golang 数组与内存布局, 方便以下内容的理解): slice := intArr[1:3] 基于intArr 数组变量 将下标为1-2的元素创建一个新的切片。图中可以看到, slice 切片变量 的两个元素内存地址其实就是对应(指向)到 intArr 数组变量 为下标1-2的元素, slice 切片变量下标为0和1的元素内存地址 = intArr 数组变量下标为1和2的元素内存地址 = 0xc00011e038 和 0xc00011e040, 从而当切片这部分元素值发生变化时, 数组的值也同时发生变化(因为都是指向同个内存地址); 相反, 当数组的值发生变化, 切片的这部分元素也发生变化, 这个应该不难理解。 切片的长度 len 表示元素的数量, 而 cap 容量则是个 倍数扩容, 比如: 当元素数量为2的时候, 容量为4; 元素数量达到4的时候, 容量为8; 元素数量达到8的时候, 容量为16 ... 依此类推 切片的声明/定义有三种方式 定义一个切片, 让切片去引用一个已经创建好的数组, 比如上述的案例就是这种方式 通过 make 来创建切片, 基本语法: var 切片名(变量名) []type = make([], len, [cap]) 参数说明: type: 数据类型 | len: 大小 | cap: 指定切片容量, 可选(如果分配了cap, 则要求 cap >= len), 用处不大, 当切片大小达到这个容量时还是可以继续 append, cap 依然会发生变化 定义一个切片, 直接指定具体数组, 使用原理类似 make 方式, 例如: var slice []string = []string{"tom", "jack", "marry"} 特别说明下 make 创建切片的内存示意图 从上面的切片声明/定义来看, ·方式1· 和 ·方式2· 是有点区别的: 方式1 是直接引用数组, 这个数组是事先存在的, 程序员是可见的。 方式2 是通过make 来创建切片, make 其实也会创建一个数组, 由切片在底层进行维护, 程序员是不可见的。 而使用append扩容的时候, 内存的变化也是不一样的。 因为底层是数组维护, 数组是没办法扩容的。 1) 如果是添加的已存在的切片变量, 比如: var vnode_slice []int vnode_slice = append(vnode_slice, 1) var slice [][]int slice = append(slice, vnode_slice) 这种情况下, 底层会直接将内存地址同时指向 vnode_slice 变量的内存地址 2) 如果是添加新的数据扩容, 比如: var slice []int slice = append(slice, 1) 这种情况下, 底层会新创建一个数组并计算 len和 cap, 将原本的数据拷贝到该新数组中, 然后把原本指向的内存地址改为指向新创建的数组内存地址, (GC)垃圾回收掉之前的数组。 这里就不一一画图了, 脑海中联想出来即可。 好了, 就先介绍到这。
Golang 切片与内存布局 切片(Slice) - 定义说明 在 Golang 中切片是一个 引用类型,在 进行传递时, 遵守引用传递机制。这种数据结构更 便于使用和管理数据集合。 切片是围绕 动态数组 的概念构建的, 可以 按需自动增长和缩小。切片的动态增长是通过内置函数 append() 来实现的, 这个函数可以快速且高效地增长切片(容量自动以切片长度的倍数扩容), 也可以通过对切片再次切割, 缩小一个切片的大小。 因为切片的底层也是在连续的内存块中分配的, 所以 切片还能获得索引、迭代以及为垃圾回收优化的好处。切片的使用和数组类似, 遍历切片、访问切片的元素和求切片的长度 len() 都一样。 我简单描述下切片的使用姿势和演示说明 package main import ( "fmt" ) func main() { // 声明/定义 var slice []int var intArr [5]int = [...]int{1, 2, 3, 4, 5} // 定义一个切片, 让切片去引用一个已经创建好的数组, 将数组下标为1的元素到下标为3的元素(不包含3) 转为切片 slice := intArr[1:3] fmt.Println(slice) // 输出: [2 3] // 改变 slice 值 slice[1] = 10 fmt.Println(slice) // 输出: [2 10] fmt.Println(intArr) // 输出: [1 2 10 4 5] (由于切片是引用类型, 所以如果切片内将这块引用内容值做修改, 将会改变 intArr 数组内容值, 下面将用内存示意图证明) fmt.Println(reflect.TypeOf(slice).Kind()) // 数据类型为切片 slice fmt.Println(len(slice), cap(slice)) // 大小为:2 容量为:4 // slice 底层可以理解为数据结构 struct 结构体 /* type slice struct { ptr *[2]int // [2]int 根据切片而变化 len int cap int } */ 就以上代码我这边整理成了内存布局, 看看内存结构是怎样的 从上面的内存图我们可以看到 (切片内存规则和数组内存规则类似, 可查阅! golang 数组与内存布局, 方便以下内容的理解): slice := intArr[1:3] 基于intArr 数组变量 将下标为1-2的元素创建一个新的切片。图中可以看到, slice 切片变量 的两个元素内存地址其实就是对应(指向)到 intArr 数组变量 为下标1-2的元素, slice 切片变量下标为0和1的元素内存地址 = intArr 数组变量下标为1和2的元素内存地址 = 0xc00011e038 和 0xc00011e040, 从而当切片这部分元素值发生变化时, 数组的值也同时发生变化(因为都是指向同个内存地址); 相反, 当数组的值发生变化, 切片的这部分元素也发生变化, 这个应该不难理解。 切片的长度 len 表示元素的数量, 而 cap 容量则是个 倍数扩容, 比如: 当元素数量为2的时候, 容量为4; 元素数量达到4的时候, 容量为8; 元素数量达到8的时候, 容量为16 ... 依此类推 切片的声明/定义有三种方式 定义一个切片, 让切片去引用一个已经创建好的数组, 比如上述的案例就是这种方式 通过 make 来创建切片, 基本语法: var 切片名(变量名) []type = make([], len, [cap]) 参数说明: type: 数据类型 | len: 大小 | cap: 指定切片容量, 可选(如果分配了cap, 则要求 cap >= len), 用处不大, 当切片大小达到这个容量时还是可以继续 append, cap 依然会发生变化 定义一个切片, 直接指定具体数组, 使用原理类似 make 方式, 例如: var slice []string = []string{"tom", "jack", "marry"} 特别说明下 make 创建切片的内存示意图 从上面的切片声明/定义来看, ·方式1· 和 ·方式2· 是有点区别的: 方式1 是直接引用数组, 这个数组是事先存在的, 程序员是可见的。 方式2 是通过make 来创建切片, make 其实也会创建一个数组, 由切片在底层进行维护, 程序员是不可见的。 而使用append扩容的时候, 内存的变化也是不一样的。 因为底层是数组维护, 数组是没办法扩容的。 1) 如果是添加的已存在的切片变量, 比如: var vnode_slice []int vnode_slice = append(vnode_slice, 1) var slice [][]int slice = append(slice, vnode_slice) 这种情况下, 底层会直接将内存地址同时指向 vnode_slice 变量的内存地址 2) 如果是添加新的数据扩容, 比如: var slice []int slice = append(slice, 1) 这种情况下, 底层会新创建一个数组并计算 len和 cap, 将原本的数据拷贝到该新数组中, 然后把原本指向的内存地址改为指向新创建的数组内存地址, (GC)垃圾回收掉之前的数组。 这里就不一一画图了, 脑海中联想出来即可。 好了, 就先介绍到这。 -
 深入理解Golang中的chan特性之上篇 Golang 的一大特色就是其简单高效的 天然并发机制。 channel 是 Golang 语言中的一个 核心数据类型, 可以把他看成通道(管道), 所以他非常重要。主要用来解决go程的同步问题以及协程之间数据共享(数据传递)的问题。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。 Golang 中使用 goroutine 和 channel 实现了 CSP (Communicating Sequential Processes) 模型, channel 在 goroutine 的通信和同步中承担着重要的角色。 goroutine 运行在相同的地址空间,因此访问共享内存必须做好同步。 goroutine 奉行通过通信来共享内存,而不是共享内存来通信。 引用类型 channel 可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。 Channel 的定义与使用 和 map 类似,channel 也是一个对应 make 创建的底层数据结构的引用。 当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel 引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。 定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建。 我们看一段代码: package main import ( "fmt" ) func main() { ch := make(chan int) // 这里就是创建一个无缓冲的 channel go func() { for i := 0; i <= 6; i++ { ch <- i // 循环写入管道数据 fmt.Println("写入管道数据", i) } }() for j := 0; j <= 6; j++ { value := <- ch // 循环读出管道数据 fmt.Println("读出管道数据", value) } } 我们在代码中 先创建了一个匿名函数的子go程,和main的主go程一起争夺 CPU,但是我们在里面创建了一个管道,无缓冲管道有一个规则那就是必须读写同时操作才会有效果,如果只进行读或者只进行写那么会被阻塞,被暂时停顿等待另外一方的操作,在这里我们定义了一个容量为0的通道,这就是无缓冲通道。 我们再看下面的代码加深 无缓冲通道 的印象 var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() select { case value := <-c: fmt.Println(value) } fmt.Println("到此为止") // 输出结果: select 阻塞了 channel 通道, 将会先等待 3秒后打印 0, 然后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() select { case value := <-c: fmt.Println(value) default: fmt.Println("我不等了") } fmt.Println("到此为止") // 输出结果: select 阻塞了 channel 通道, 但是有带 default, 将会直接打印 '我不等了', 然后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() fmt.Println("等待中") <-c fmt.Println("到此为止") // 输出结果: 先打印 '等待中', 等待 3秒后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() fmt.Println("等待中") value := <-c fmt.Println(value) fmt.Println("到此为止") // 输出结果: 先打印 '等待中', 等待 3秒后打印 0, 然后打印 '到此为止' 使用无缓冲的通道在 Goroutine 之间同步数据 (一次只能传输一个数据) 总结一下就是无缓冲特性: 同一时刻,同时有 读、写两端把持 channel 如果只有读端,没有写端,那么 “读端”阻塞 如果只有写端,没有读端,那么 “写端”阻塞 读channel: <- channel 写channel: channel <- 数据 使用有缓冲的通道在 Goroutine 之间同步数据 (读写数据可以同时进行) 我来描述下上面的步骤: 第一步 | 右侧的 goroutine 正在从通道接收一个值。 第二步 | 右侧的这个 goroutine 独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。 第三步 | 左侧的 goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。 第四步 | 所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。 有缓冲通道就是图中所示,一方可以写入很多数据,不用等对方的操作,而另外一方也可以直接拿出数据,不需要等对方写,但是注意一点(如果写入的一方把channel写满了,那么如果要继续写就要等对方取数据后才能继续写入,这也是一种阻塞,读出数据也是一样,如果里面没有数据则不能取,就要等对方写入)。 有缓冲channel的定义很简单: ch := make(chan int, 10) // chan int 只能写入读入int类型的数据, 10代表容量。 总结一下就是有缓冲特性: 写数据时, 直到缓冲区被填满后,“写端”才会阻塞 读数据时, 缓冲区被读空,“读端”才会阻塞 len: 代表缓冲区中,剩余元素个数 cap: 代表缓冲区的容量 最后, 举个简单的例子再次帮助理解 channel: 同步通信 (无缓冲channel): 数据发送端,和数据接收端,必须同时在线。 比如打电话, 只有等对方接收才会通,要不然只能阻塞。 异步通信 (有缓冲channel): 数据发送端 发送完数据后立即返回。数据接收端 有可能立即读取,也可能延迟处理。 不用等对方接受, 只需发送过去就行, 比如发短信, 发邮件...
深入理解Golang中的chan特性之上篇 Golang 的一大特色就是其简单高效的 天然并发机制。 channel 是 Golang 语言中的一个 核心数据类型, 可以把他看成通道(管道), 所以他非常重要。主要用来解决go程的同步问题以及协程之间数据共享(数据传递)的问题。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。 Golang 中使用 goroutine 和 channel 实现了 CSP (Communicating Sequential Processes) 模型, channel 在 goroutine 的通信和同步中承担着重要的角色。 goroutine 运行在相同的地址空间,因此访问共享内存必须做好同步。 goroutine 奉行通过通信来共享内存,而不是共享内存来通信。 引用类型 channel 可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。 Channel 的定义与使用 和 map 类似,channel 也是一个对应 make 创建的底层数据结构的引用。 当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel 引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。 定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建。 我们看一段代码: package main import ( "fmt" ) func main() { ch := make(chan int) // 这里就是创建一个无缓冲的 channel go func() { for i := 0; i <= 6; i++ { ch <- i // 循环写入管道数据 fmt.Println("写入管道数据", i) } }() for j := 0; j <= 6; j++ { value := <- ch // 循环读出管道数据 fmt.Println("读出管道数据", value) } } 我们在代码中 先创建了一个匿名函数的子go程,和main的主go程一起争夺 CPU,但是我们在里面创建了一个管道,无缓冲管道有一个规则那就是必须读写同时操作才会有效果,如果只进行读或者只进行写那么会被阻塞,被暂时停顿等待另外一方的操作,在这里我们定义了一个容量为0的通道,这就是无缓冲通道。 我们再看下面的代码加深 无缓冲通道 的印象 var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() select { case value := <-c: fmt.Println(value) } fmt.Println("到此为止") // 输出结果: select 阻塞了 channel 通道, 将会先等待 3秒后打印 0, 然后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() select { case value := <-c: fmt.Println(value) default: fmt.Println("我不等了") } fmt.Println("到此为止") // 输出结果: select 阻塞了 channel 通道, 但是有带 default, 将会直接打印 '我不等了', 然后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() fmt.Println("等待中") <-c fmt.Println("到此为止") // 输出结果: 先打印 '等待中', 等待 3秒后打印 '到此为止' var c = make(chan int) go func() { // 等待 3秒后循环写入值到通道 time.Sleep(3 * time.Second) for i := 0; i < 5; i++ { c <- i } }() fmt.Println("等待中") value := <-c fmt.Println(value) fmt.Println("到此为止") // 输出结果: 先打印 '等待中', 等待 3秒后打印 0, 然后打印 '到此为止' 使用无缓冲的通道在 Goroutine 之间同步数据 (一次只能传输一个数据) 总结一下就是无缓冲特性: 同一时刻,同时有 读、写两端把持 channel 如果只有读端,没有写端,那么 “读端”阻塞 如果只有写端,没有读端,那么 “写端”阻塞 读channel: <- channel 写channel: channel <- 数据 使用有缓冲的通道在 Goroutine 之间同步数据 (读写数据可以同时进行) 我来描述下上面的步骤: 第一步 | 右侧的 goroutine 正在从通道接收一个值。 第二步 | 右侧的这个 goroutine 独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。 第三步 | 左侧的 goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。 第四步 | 所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。 有缓冲通道就是图中所示,一方可以写入很多数据,不用等对方的操作,而另外一方也可以直接拿出数据,不需要等对方写,但是注意一点(如果写入的一方把channel写满了,那么如果要继续写就要等对方取数据后才能继续写入,这也是一种阻塞,读出数据也是一样,如果里面没有数据则不能取,就要等对方写入)。 有缓冲channel的定义很简单: ch := make(chan int, 10) // chan int 只能写入读入int类型的数据, 10代表容量。 总结一下就是有缓冲特性: 写数据时, 直到缓冲区被填满后,“写端”才会阻塞 读数据时, 缓冲区被读空,“读端”才会阻塞 len: 代表缓冲区中,剩余元素个数 cap: 代表缓冲区的容量 最后, 举个简单的例子再次帮助理解 channel: 同步通信 (无缓冲channel): 数据发送端,和数据接收端,必须同时在线。 比如打电话, 只有等对方接收才会通,要不然只能阻塞。 异步通信 (有缓冲channel): 数据发送端 发送完数据后立即返回。数据接收端 有可能立即读取,也可能延迟处理。 不用等对方接受, 只需发送过去就行, 比如发短信, 发邮件... -
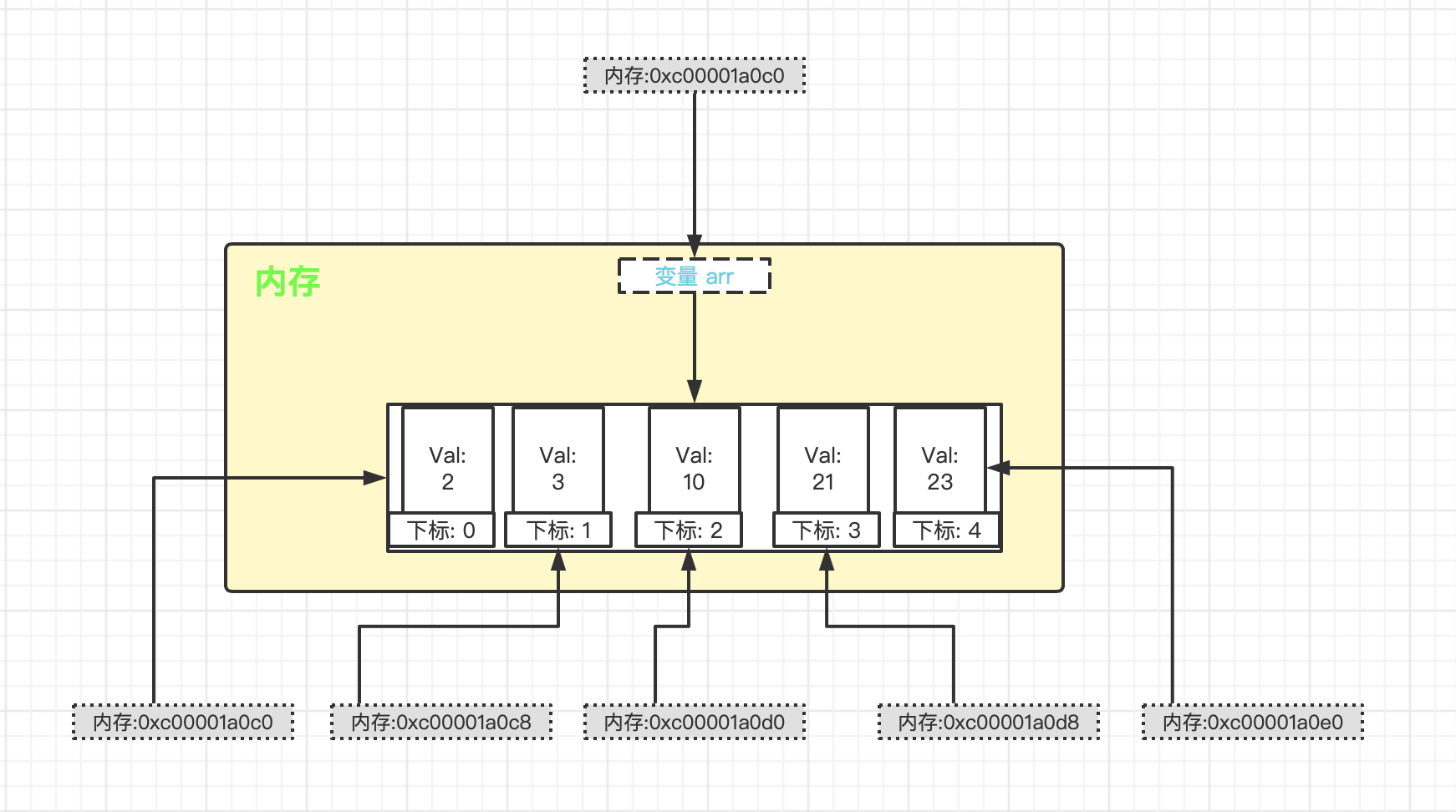 GoLang 数组与内存布局 数组(Array) - 定义说明 在 Golang 中数组是一个 值类型。如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。 我简单描述下数组的使用姿势和演示说明 package main import "fmt" func main() { /* 1) 四种初始化数组的方式 var arr1 [3]int = [3]int{1, 2, 3} var arr2 = [3]int{1, 2, 3} var arr3 = [...]int{1, 2, 3} // 程序自动判断数组长度 var arr4 = [3]string{1: "tom", 2: "marry", 0: "jack"} 2) 常规遍历数组 var arr = [3]int{1, 2, 3} for i := 0; i < len(arr); i++ { ... } 3) for-range 结构遍历数组 var arr = [3]int{1, 2, 3} for index, value := range arr { ... } 说明 1. 第一个返回值 index 是数组的下标 2. 第二个 value 是该下标位置对应的值 3. 他们都是仅在 for 循环内部可见的局部变量 4. 遍历数组元素的时候, 如果不想使用下标 index, 可以直接把下标 index 标为下划线 _ 表示 */ var ( arr [5]int // 数组长度是定长的(固定的), 当我们定义完数组后, 数组的各个元素的默认值都是0 ) arr[0], arr[1], arr[2], arr[3], arr[4] = 2, 3, 10, 21, 23 arrValue := 0 for i := 0; i < len(arr); i++ { arrValue += arr[i] } fmt.Println(arrValue) // 输出: 59 } 数组使用的注意事项和细节 数组是多个 相同类型 数据的集合, 一个数组一旦声明/定义, 其 长度是固定的, 不能动态变化。(如果要动态变化, 可以使用切片) 数组中的元素可以是任何数据类型, 包括值类型和引用类型, 但是 不能混用。 数组创建后, 如果没有赋值, 有默认值(零值)。 数组的下标都是从 0 开始的 数组的下标必须在指定的范围内使用, 否则报 panic 数组越界, 比如: var arr [5]int 则有效下标为 0-4 Go 的数组属 值类型, 在默认情况下是值传递, 因此会进行值拷贝, 数组间不会相互影响。 如果想在其他函数中去修改原来的数组值, 可以使用引用传递(指针方式) - [可以自行了解下栈原理], 例如: var arr [3]int func updateArr(arr [3]int) { (arr)[0] = 10 // arr[0] = 10 } updateArr(&arr) // 此时 arr 变量的内容为 {10, 0, 0}, 通过指针方式将数组数据修改 长度是数组类型的一部分, 在传递函数参数的时候, 需要考虑数组的长度。 从使用上来说没有什么难度, 在这也就不细说, 我将把重点放在内存原理上。 我们看看上述代码的数组在内存里是怎么存放的 从上面的内存图我们可以看到: 数组变量 arr 的内存地址和 数组下标为0 的内存地址是一样的, 由此分析出 数组的第一个元素内存地址就是数组变量的内存地址, 这个应该不会太难理解, 因为数组的第一个元素标志着该数组的存在。 可以看到这5个元素的内存地址其实是有规律的 元素1 0xc00001a0c0 元素2 0xc00001a0c8 元素3 0xc00001a0d0 元素4 0xc00001a0d8 元素5 0xc00001a0e0 尾数都是 0 和 8, 当尾数到 8 时, 前位数 进1, 比如 c 进 d, 2 进 3 ... 主要原因就是因为 int 类型是 8字节 的。如果数组是其他的数据类型也是一样, 根据不同的数据类型占用的字节数 满字节后进1。 (例如: int8 是占用1个字节, int16 是占用2个字节, string 是占用16个字节, 你可以通过 unsafe.Sizeof(arr) 函数查看字节占用) 如果有第六个元素, 那么它的地址应该是 0xc00001a0e8。 好了, 就先介绍到这。
GoLang 数组与内存布局 数组(Array) - 定义说明 在 Golang 中数组是一个 值类型。如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。 我简单描述下数组的使用姿势和演示说明 package main import "fmt" func main() { /* 1) 四种初始化数组的方式 var arr1 [3]int = [3]int{1, 2, 3} var arr2 = [3]int{1, 2, 3} var arr3 = [...]int{1, 2, 3} // 程序自动判断数组长度 var arr4 = [3]string{1: "tom", 2: "marry", 0: "jack"} 2) 常规遍历数组 var arr = [3]int{1, 2, 3} for i := 0; i < len(arr); i++ { ... } 3) for-range 结构遍历数组 var arr = [3]int{1, 2, 3} for index, value := range arr { ... } 说明 1. 第一个返回值 index 是数组的下标 2. 第二个 value 是该下标位置对应的值 3. 他们都是仅在 for 循环内部可见的局部变量 4. 遍历数组元素的时候, 如果不想使用下标 index, 可以直接把下标 index 标为下划线 _ 表示 */ var ( arr [5]int // 数组长度是定长的(固定的), 当我们定义完数组后, 数组的各个元素的默认值都是0 ) arr[0], arr[1], arr[2], arr[3], arr[4] = 2, 3, 10, 21, 23 arrValue := 0 for i := 0; i < len(arr); i++ { arrValue += arr[i] } fmt.Println(arrValue) // 输出: 59 } 数组使用的注意事项和细节 数组是多个 相同类型 数据的集合, 一个数组一旦声明/定义, 其 长度是固定的, 不能动态变化。(如果要动态变化, 可以使用切片) 数组中的元素可以是任何数据类型, 包括值类型和引用类型, 但是 不能混用。 数组创建后, 如果没有赋值, 有默认值(零值)。 数组的下标都是从 0 开始的 数组的下标必须在指定的范围内使用, 否则报 panic 数组越界, 比如: var arr [5]int 则有效下标为 0-4 Go 的数组属 值类型, 在默认情况下是值传递, 因此会进行值拷贝, 数组间不会相互影响。 如果想在其他函数中去修改原来的数组值, 可以使用引用传递(指针方式) - [可以自行了解下栈原理], 例如: var arr [3]int func updateArr(arr [3]int) { (arr)[0] = 10 // arr[0] = 10 } updateArr(&arr) // 此时 arr 变量的内容为 {10, 0, 0}, 通过指针方式将数组数据修改 长度是数组类型的一部分, 在传递函数参数的时候, 需要考虑数组的长度。 从使用上来说没有什么难度, 在这也就不细说, 我将把重点放在内存原理上。 我们看看上述代码的数组在内存里是怎么存放的 从上面的内存图我们可以看到: 数组变量 arr 的内存地址和 数组下标为0 的内存地址是一样的, 由此分析出 数组的第一个元素内存地址就是数组变量的内存地址, 这个应该不会太难理解, 因为数组的第一个元素标志着该数组的存在。 可以看到这5个元素的内存地址其实是有规律的 元素1 0xc00001a0c0 元素2 0xc00001a0c8 元素3 0xc00001a0d0 元素4 0xc00001a0d8 元素5 0xc00001a0e0 尾数都是 0 和 8, 当尾数到 8 时, 前位数 进1, 比如 c 进 d, 2 进 3 ... 主要原因就是因为 int 类型是 8字节 的。如果数组是其他的数据类型也是一样, 根据不同的数据类型占用的字节数 满字节后进1。 (例如: int8 是占用1个字节, int16 是占用2个字节, string 是占用16个字节, 你可以通过 unsafe.Sizeof(arr) 函数查看字节占用) 如果有第六个元素, 那么它的地址应该是 0xc00001a0e8。 好了, 就先介绍到这。 -
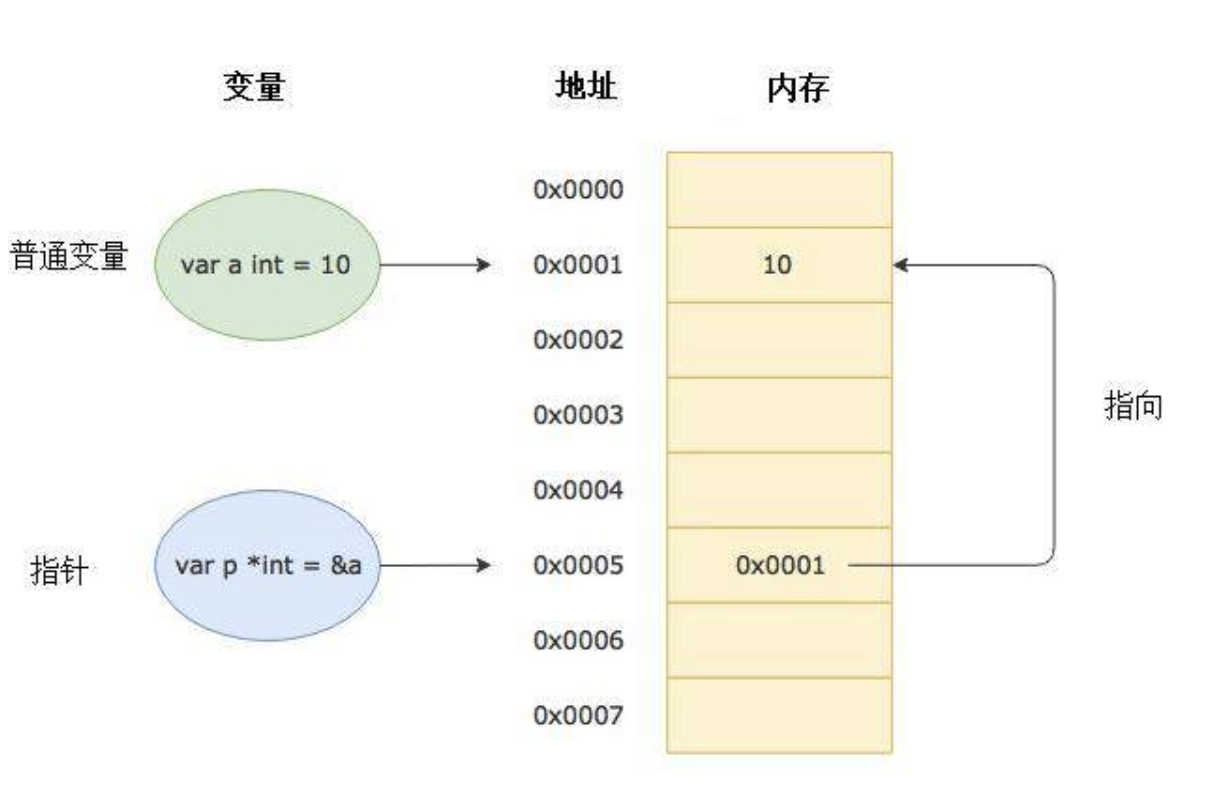 玩转 GoLang 指针 什么是指针? 指针其实就是一个变量, 用于存储另一个变量的内存地址。 那么什么是变量呢?在现代计算机体系结构中所有的需要执行的信息代码都需要存储在内存中,为了管理存储在内存的数据,内存是划分为不同的区域的,不同区域都用内存地址来标识。一个典型的内存地址是个16进制的8位数(一个字节)比如0xAFFFF(这是一个内存地址的十六进制表示)。 要访问数据,我们需要知道它的存储地址。我们可以跟踪存储与我们的程序相关的数据的所有内存地址。但是要记住这些内存地址,非常费劲,怎么办呢? 于是我们引入了变量的概念。变量只是给存储数据的内存地址的好记的别名。指针也是一个变量。但它是一种特殊的变量,因为它存储的数据不仅仅是一个普通的值(如整数或字符串),而是另一个变量的内存地址。 在上面的图中,指针p 指向 变量a 的地址值0x0001, 那么 指针p 的值是跟随 变量a 的地址值变化而变化的。 指针声明 T类型的指针使用以下语法声明: var p *int // 表示 p指针 只能保存int变量的内存地址。 指针的零值,不是0,而是nil。任何未初始化的指针值都为nil 初始化指针、指针解引用及指针值修改 初始化一个指针,只需给他赋予其他变量的内存地址。变量的地址可以使用使用&运算符获得: var x int = 199 var p *int = &x // 也可以简写为: var p = &x -> 编译器会自动推断指针变量的数据类型 fmt.Println(p) // 输出指针p的值, 即变量x的内存地址: 0xc0000b2008 // 获得指针指向地址的值, 也叫做解引用 fmt.Println(*p) // 输出指针p对应变量x 内存地址的值: 199 (也可以说是指针p的内存地址对应的值). fmt.Println(&p) // 输出指针p的内存地址: 0xc00001a0b8 fmt.Println(*&p) // 输出指针p的内存地址对应的值, 即变量x的内存地址: 0xc0000b2008 , 同 fmt.Println(&*p) 的结果是一样的 // 修改指针变量的值 *p += 100 fmt.Println(*p) // 输出: 299 通过上面代码的解释, 应该也基本理解了指针。 多重指针 指针可以指向任何类型的变量, 所以也可以指向另一个指针。 var x int = 199 var p *int = &x var pp **int = &p fmt.Println(**pp) // 输出: 199 (原理其实是一样的, 只是一层层取值而已) Go 中没有指针算术 在 C/C++ 中是可以对指针做计算的,但是 Golang 就不支持那样做了。 var x int = 199 var p *int = &x var p1 = p + 1 // Compiler Error: invalid operation 但是,Golang 中可以使用 == 运算符来比较两个相同类型的指针是否相等。 var x int = 199 var p *int = &x var p1 *int = &x if p == p1 { fmt.Println("ok") } else { fmt.Println("no") } 当然, 对于 Golang 算术, 仅仅依靠 == 运算符来说事, 确实显得很勉强。
玩转 GoLang 指针 什么是指针? 指针其实就是一个变量, 用于存储另一个变量的内存地址。 那么什么是变量呢?在现代计算机体系结构中所有的需要执行的信息代码都需要存储在内存中,为了管理存储在内存的数据,内存是划分为不同的区域的,不同区域都用内存地址来标识。一个典型的内存地址是个16进制的8位数(一个字节)比如0xAFFFF(这是一个内存地址的十六进制表示)。 要访问数据,我们需要知道它的存储地址。我们可以跟踪存储与我们的程序相关的数据的所有内存地址。但是要记住这些内存地址,非常费劲,怎么办呢? 于是我们引入了变量的概念。变量只是给存储数据的内存地址的好记的别名。指针也是一个变量。但它是一种特殊的变量,因为它存储的数据不仅仅是一个普通的值(如整数或字符串),而是另一个变量的内存地址。 在上面的图中,指针p 指向 变量a 的地址值0x0001, 那么 指针p 的值是跟随 变量a 的地址值变化而变化的。 指针声明 T类型的指针使用以下语法声明: var p *int // 表示 p指针 只能保存int变量的内存地址。 指针的零值,不是0,而是nil。任何未初始化的指针值都为nil 初始化指针、指针解引用及指针值修改 初始化一个指针,只需给他赋予其他变量的内存地址。变量的地址可以使用使用&运算符获得: var x int = 199 var p *int = &x // 也可以简写为: var p = &x -> 编译器会自动推断指针变量的数据类型 fmt.Println(p) // 输出指针p的值, 即变量x的内存地址: 0xc0000b2008 // 获得指针指向地址的值, 也叫做解引用 fmt.Println(*p) // 输出指针p对应变量x 内存地址的值: 199 (也可以说是指针p的内存地址对应的值). fmt.Println(&p) // 输出指针p的内存地址: 0xc00001a0b8 fmt.Println(*&p) // 输出指针p的内存地址对应的值, 即变量x的内存地址: 0xc0000b2008 , 同 fmt.Println(&*p) 的结果是一样的 // 修改指针变量的值 *p += 100 fmt.Println(*p) // 输出: 299 通过上面代码的解释, 应该也基本理解了指针。 多重指针 指针可以指向任何类型的变量, 所以也可以指向另一个指针。 var x int = 199 var p *int = &x var pp **int = &p fmt.Println(**pp) // 输出: 199 (原理其实是一样的, 只是一层层取值而已) Go 中没有指针算术 在 C/C++ 中是可以对指针做计算的,但是 Golang 就不支持那样做了。 var x int = 199 var p *int = &x var p1 = p + 1 // Compiler Error: invalid operation 但是,Golang 中可以使用 == 运算符来比较两个相同类型的指针是否相等。 var x int = 199 var p *int = &x var p1 *int = &x if p == p1 { fmt.Println("ok") } else { fmt.Println("no") } 当然, 对于 Golang 算术, 仅仅依靠 == 运算符来说事, 确实显得很勉强。