-
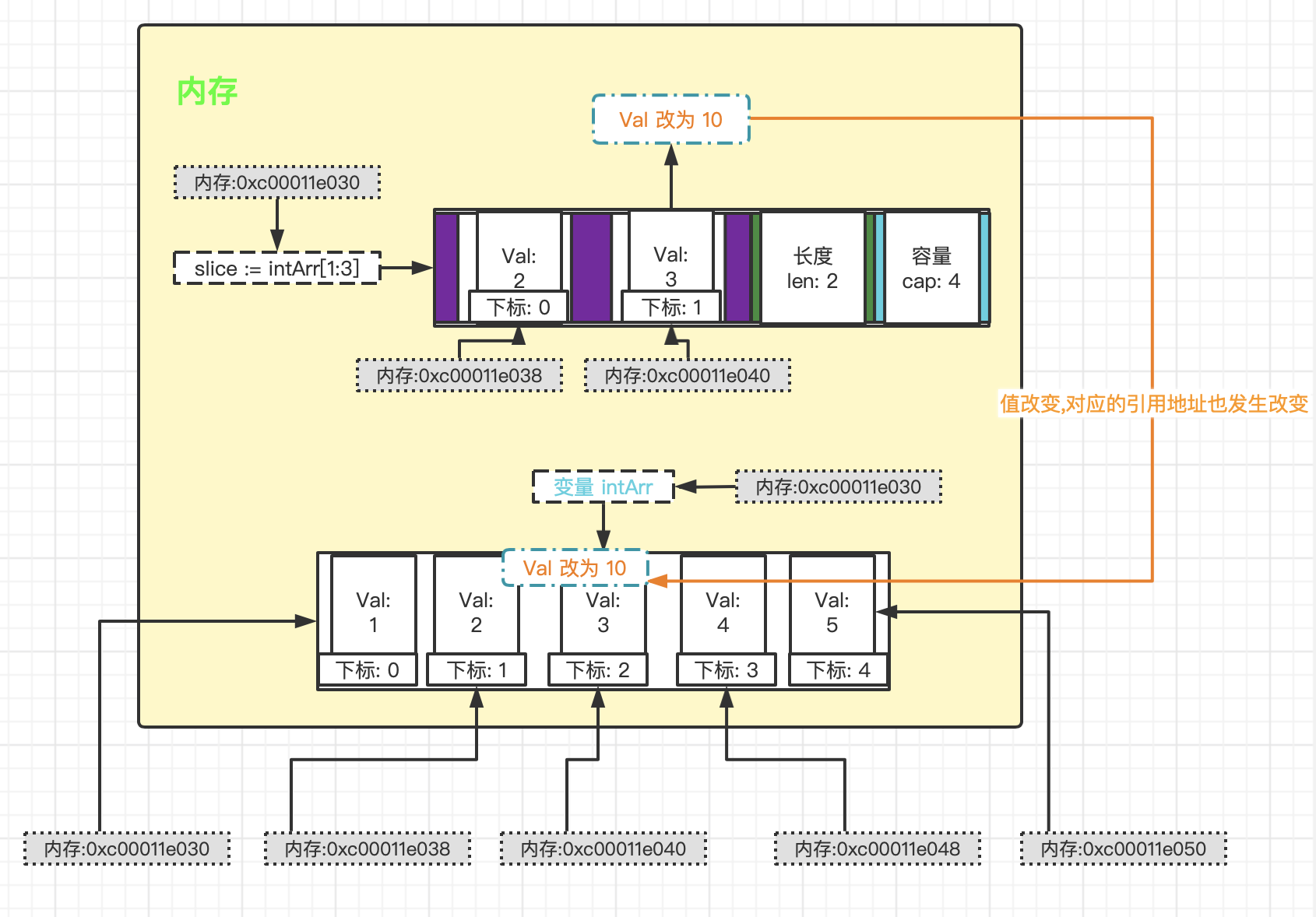 Golang 切片与内存布局 切片(Slice) - 定义说明 在 Golang 中切片是一个 引用类型,在 进行传递时, 遵守引用传递机制。这种数据结构更 便于使用和管理数据集合。 切片是围绕 动态数组 的概念构建的, 可以 按需自动增长和缩小。切片的动态增长是通过内置函数 append() 来实现的, 这个函数可以快速且高效地增长切片(容量自动以切片长度的倍数扩容), 也可以通过对切片再次切割, 缩小一个切片的大小。 因为切片的底层也是在连续的内存块中分配的, 所以 切片还能获得索引、迭代以及为垃圾回收优化的好处。切片的使用和数组类似, 遍历切片、访问切片的元素和求切片的长度 len() 都一样。 我简单描述下切片的使用姿势和演示说明 package main import ( "fmt" ) func main() { // 声明/定义 var slice []int var intArr [5]int = [...]int{1, 2, 3, 4, 5} // 定义一个切片, 让切片去引用一个已经创建好的数组, 将数组下标为1的元素到下标为3的元素(不包含3) 转为切片 slice := intArr[1:3] fmt.Println(slice) // 输出: [2 3] // 改变 slice 值 slice[1] = 10 fmt.Println(slice) // 输出: [2 10] fmt.Println(intArr) // 输出: [1 2 10 4 5] (由于切片是引用类型, 所以如果切片内将这块引用内容值做修改, 将会改变 intArr 数组内容值, 下面将用内存示意图证明) fmt.Println(reflect.TypeOf(slice).Kind()) // 数据类型为切片 slice fmt.Println(len(slice), cap(slice)) // 大小为:2 容量为:4 // slice 底层可以理解为数据结构 struct 结构体 /* type slice struct { ptr *[2]int // [2]int 根据切片而变化 len int cap int } */ 就以上代码我这边整理成了内存布局, 看看内存结构是怎样的 从上面的内存图我们可以看到 (切片内存规则和数组内存规则类似, 可查阅! golang 数组与内存布局, 方便以下内容的理解): slice := intArr[1:3] 基于intArr 数组变量 将下标为1-2的元素创建一个新的切片。图中可以看到, slice 切片变量 的两个元素内存地址其实就是对应(指向)到 intArr 数组变量 为下标1-2的元素, slice 切片变量下标为0和1的元素内存地址 = intArr 数组变量下标为1和2的元素内存地址 = 0xc00011e038 和 0xc00011e040, 从而当切片这部分元素值发生变化时, 数组的值也同时发生变化(因为都是指向同个内存地址); 相反, 当数组的值发生变化, 切片的这部分元素也发生变化, 这个应该不难理解。 切片的长度 len 表示元素的数量, 而 cap 容量则是个 倍数扩容, 比如: 当元素数量为2的时候, 容量为4; 元素数量达到4的时候, 容量为8; 元素数量达到8的时候, 容量为16 ... 依此类推 切片的声明/定义有三种方式 定义一个切片, 让切片去引用一个已经创建好的数组, 比如上述的案例就是这种方式 通过 make 来创建切片, 基本语法: var 切片名(变量名) []type = make([], len, [cap]) 参数说明: type: 数据类型 | len: 大小 | cap: 指定切片容量, 可选(如果分配了cap, 则要求 cap >= len), 用处不大, 当切片大小达到这个容量时还是可以继续 append, cap 依然会发生变化 定义一个切片, 直接指定具体数组, 使用原理类似 make 方式, 例如: var slice []string = []string{"tom", "jack", "marry"} 特别说明下 make 创建切片的内存示意图 从上面的切片声明/定义来看, ·方式1· 和 ·方式2· 是有点区别的: 方式1 是直接引用数组, 这个数组是事先存在的, 程序员是可见的。 方式2 是通过make 来创建切片, make 其实也会创建一个数组, 由切片在底层进行维护, 程序员是不可见的。 而使用append扩容的时候, 内存的变化也是不一样的。 因为底层是数组维护, 数组是没办法扩容的。 1) 如果是添加的已存在的切片变量, 比如: var vnode_slice []int vnode_slice = append(vnode_slice, 1) var slice [][]int slice = append(slice, vnode_slice) 这种情况下, 底层会直接将内存地址同时指向 vnode_slice 变量的内存地址 2) 如果是添加新的数据扩容, 比如: var slice []int slice = append(slice, 1) 这种情况下, 底层会新创建一个数组并计算 len和 cap, 将原本的数据拷贝到该新数组中, 然后把原本指向的内存地址改为指向新创建的数组内存地址, (GC)垃圾回收掉之前的数组。 这里就不一一画图了, 脑海中联想出来即可。 好了, 就先介绍到这。
Golang 切片与内存布局 切片(Slice) - 定义说明 在 Golang 中切片是一个 引用类型,在 进行传递时, 遵守引用传递机制。这种数据结构更 便于使用和管理数据集合。 切片是围绕 动态数组 的概念构建的, 可以 按需自动增长和缩小。切片的动态增长是通过内置函数 append() 来实现的, 这个函数可以快速且高效地增长切片(容量自动以切片长度的倍数扩容), 也可以通过对切片再次切割, 缩小一个切片的大小。 因为切片的底层也是在连续的内存块中分配的, 所以 切片还能获得索引、迭代以及为垃圾回收优化的好处。切片的使用和数组类似, 遍历切片、访问切片的元素和求切片的长度 len() 都一样。 我简单描述下切片的使用姿势和演示说明 package main import ( "fmt" ) func main() { // 声明/定义 var slice []int var intArr [5]int = [...]int{1, 2, 3, 4, 5} // 定义一个切片, 让切片去引用一个已经创建好的数组, 将数组下标为1的元素到下标为3的元素(不包含3) 转为切片 slice := intArr[1:3] fmt.Println(slice) // 输出: [2 3] // 改变 slice 值 slice[1] = 10 fmt.Println(slice) // 输出: [2 10] fmt.Println(intArr) // 输出: [1 2 10 4 5] (由于切片是引用类型, 所以如果切片内将这块引用内容值做修改, 将会改变 intArr 数组内容值, 下面将用内存示意图证明) fmt.Println(reflect.TypeOf(slice).Kind()) // 数据类型为切片 slice fmt.Println(len(slice), cap(slice)) // 大小为:2 容量为:4 // slice 底层可以理解为数据结构 struct 结构体 /* type slice struct { ptr *[2]int // [2]int 根据切片而变化 len int cap int } */ 就以上代码我这边整理成了内存布局, 看看内存结构是怎样的 从上面的内存图我们可以看到 (切片内存规则和数组内存规则类似, 可查阅! golang 数组与内存布局, 方便以下内容的理解): slice := intArr[1:3] 基于intArr 数组变量 将下标为1-2的元素创建一个新的切片。图中可以看到, slice 切片变量 的两个元素内存地址其实就是对应(指向)到 intArr 数组变量 为下标1-2的元素, slice 切片变量下标为0和1的元素内存地址 = intArr 数组变量下标为1和2的元素内存地址 = 0xc00011e038 和 0xc00011e040, 从而当切片这部分元素值发生变化时, 数组的值也同时发生变化(因为都是指向同个内存地址); 相反, 当数组的值发生变化, 切片的这部分元素也发生变化, 这个应该不难理解。 切片的长度 len 表示元素的数量, 而 cap 容量则是个 倍数扩容, 比如: 当元素数量为2的时候, 容量为4; 元素数量达到4的时候, 容量为8; 元素数量达到8的时候, 容量为16 ... 依此类推 切片的声明/定义有三种方式 定义一个切片, 让切片去引用一个已经创建好的数组, 比如上述的案例就是这种方式 通过 make 来创建切片, 基本语法: var 切片名(变量名) []type = make([], len, [cap]) 参数说明: type: 数据类型 | len: 大小 | cap: 指定切片容量, 可选(如果分配了cap, 则要求 cap >= len), 用处不大, 当切片大小达到这个容量时还是可以继续 append, cap 依然会发生变化 定义一个切片, 直接指定具体数组, 使用原理类似 make 方式, 例如: var slice []string = []string{"tom", "jack", "marry"} 特别说明下 make 创建切片的内存示意图 从上面的切片声明/定义来看, ·方式1· 和 ·方式2· 是有点区别的: 方式1 是直接引用数组, 这个数组是事先存在的, 程序员是可见的。 方式2 是通过make 来创建切片, make 其实也会创建一个数组, 由切片在底层进行维护, 程序员是不可见的。 而使用append扩容的时候, 内存的变化也是不一样的。 因为底层是数组维护, 数组是没办法扩容的。 1) 如果是添加的已存在的切片变量, 比如: var vnode_slice []int vnode_slice = append(vnode_slice, 1) var slice [][]int slice = append(slice, vnode_slice) 这种情况下, 底层会直接将内存地址同时指向 vnode_slice 变量的内存地址 2) 如果是添加新的数据扩容, 比如: var slice []int slice = append(slice, 1) 这种情况下, 底层会新创建一个数组并计算 len和 cap, 将原本的数据拷贝到该新数组中, 然后把原本指向的内存地址改为指向新创建的数组内存地址, (GC)垃圾回收掉之前的数组。 这里就不一一画图了, 脑海中联想出来即可。 好了, 就先介绍到这。 -
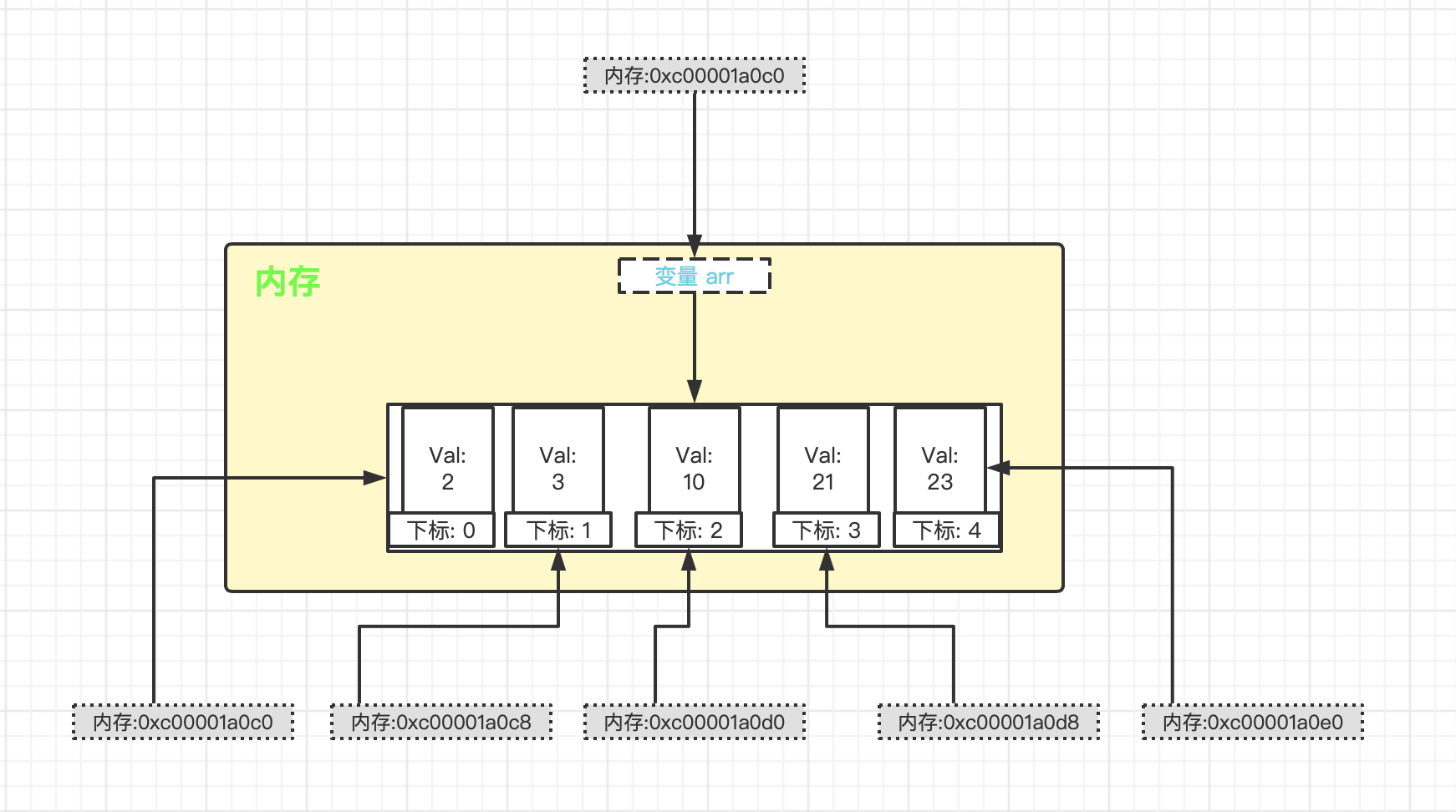 GoLang 数组与内存布局 数组(Array) - 定义说明 在 Golang 中数组是一个 值类型。如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。 我简单描述下数组的使用姿势和演示说明 package main import "fmt" func main() { /* 1) 四种初始化数组的方式 var arr1 [3]int = [3]int{1, 2, 3} var arr2 = [3]int{1, 2, 3} var arr3 = [...]int{1, 2, 3} // 程序自动判断数组长度 var arr4 = [3]string{1: "tom", 2: "marry", 0: "jack"} 2) 常规遍历数组 var arr = [3]int{1, 2, 3} for i := 0; i < len(arr); i++ { ... } 3) for-range 结构遍历数组 var arr = [3]int{1, 2, 3} for index, value := range arr { ... } 说明 1. 第一个返回值 index 是数组的下标 2. 第二个 value 是该下标位置对应的值 3. 他们都是仅在 for 循环内部可见的局部变量 4. 遍历数组元素的时候, 如果不想使用下标 index, 可以直接把下标 index 标为下划线 _ 表示 */ var ( arr [5]int // 数组长度是定长的(固定的), 当我们定义完数组后, 数组的各个元素的默认值都是0 ) arr[0], arr[1], arr[2], arr[3], arr[4] = 2, 3, 10, 21, 23 arrValue := 0 for i := 0; i < len(arr); i++ { arrValue += arr[i] } fmt.Println(arrValue) // 输出: 59 } 数组使用的注意事项和细节 数组是多个 相同类型 数据的集合, 一个数组一旦声明/定义, 其 长度是固定的, 不能动态变化。(如果要动态变化, 可以使用切片) 数组中的元素可以是任何数据类型, 包括值类型和引用类型, 但是 不能混用。 数组创建后, 如果没有赋值, 有默认值(零值)。 数组的下标都是从 0 开始的 数组的下标必须在指定的范围内使用, 否则报 panic 数组越界, 比如: var arr [5]int 则有效下标为 0-4 Go 的数组属 值类型, 在默认情况下是值传递, 因此会进行值拷贝, 数组间不会相互影响。 如果想在其他函数中去修改原来的数组值, 可以使用引用传递(指针方式) - [可以自行了解下栈原理], 例如: var arr [3]int func updateArr(arr [3]int) { (arr)[0] = 10 // arr[0] = 10 } updateArr(&arr) // 此时 arr 变量的内容为 {10, 0, 0}, 通过指针方式将数组数据修改 长度是数组类型的一部分, 在传递函数参数的时候, 需要考虑数组的长度。 从使用上来说没有什么难度, 在这也就不细说, 我将把重点放在内存原理上。 我们看看上述代码的数组在内存里是怎么存放的 从上面的内存图我们可以看到: 数组变量 arr 的内存地址和 数组下标为0 的内存地址是一样的, 由此分析出 数组的第一个元素内存地址就是数组变量的内存地址, 这个应该不会太难理解, 因为数组的第一个元素标志着该数组的存在。 可以看到这5个元素的内存地址其实是有规律的 元素1 0xc00001a0c0 元素2 0xc00001a0c8 元素3 0xc00001a0d0 元素4 0xc00001a0d8 元素5 0xc00001a0e0 尾数都是 0 和 8, 当尾数到 8 时, 前位数 进1, 比如 c 进 d, 2 进 3 ... 主要原因就是因为 int 类型是 8字节 的。如果数组是其他的数据类型也是一样, 根据不同的数据类型占用的字节数 满字节后进1。 (例如: int8 是占用1个字节, int16 是占用2个字节, string 是占用16个字节, 你可以通过 unsafe.Sizeof(arr) 函数查看字节占用) 如果有第六个元素, 那么它的地址应该是 0xc00001a0e8。 好了, 就先介绍到这。
GoLang 数组与内存布局 数组(Array) - 定义说明 在 Golang 中数组是一个 值类型。如果将数组作为函数的参数类型,则在函数调用时该参数将发生数据复制。因此,在函数体中无法修改传入的数组的内容,因为函数内操作的只是所传入数组的一个副本。 我简单描述下数组的使用姿势和演示说明 package main import "fmt" func main() { /* 1) 四种初始化数组的方式 var arr1 [3]int = [3]int{1, 2, 3} var arr2 = [3]int{1, 2, 3} var arr3 = [...]int{1, 2, 3} // 程序自动判断数组长度 var arr4 = [3]string{1: "tom", 2: "marry", 0: "jack"} 2) 常规遍历数组 var arr = [3]int{1, 2, 3} for i := 0; i < len(arr); i++ { ... } 3) for-range 结构遍历数组 var arr = [3]int{1, 2, 3} for index, value := range arr { ... } 说明 1. 第一个返回值 index 是数组的下标 2. 第二个 value 是该下标位置对应的值 3. 他们都是仅在 for 循环内部可见的局部变量 4. 遍历数组元素的时候, 如果不想使用下标 index, 可以直接把下标 index 标为下划线 _ 表示 */ var ( arr [5]int // 数组长度是定长的(固定的), 当我们定义完数组后, 数组的各个元素的默认值都是0 ) arr[0], arr[1], arr[2], arr[3], arr[4] = 2, 3, 10, 21, 23 arrValue := 0 for i := 0; i < len(arr); i++ { arrValue += arr[i] } fmt.Println(arrValue) // 输出: 59 } 数组使用的注意事项和细节 数组是多个 相同类型 数据的集合, 一个数组一旦声明/定义, 其 长度是固定的, 不能动态变化。(如果要动态变化, 可以使用切片) 数组中的元素可以是任何数据类型, 包括值类型和引用类型, 但是 不能混用。 数组创建后, 如果没有赋值, 有默认值(零值)。 数组的下标都是从 0 开始的 数组的下标必须在指定的范围内使用, 否则报 panic 数组越界, 比如: var arr [5]int 则有效下标为 0-4 Go 的数组属 值类型, 在默认情况下是值传递, 因此会进行值拷贝, 数组间不会相互影响。 如果想在其他函数中去修改原来的数组值, 可以使用引用传递(指针方式) - [可以自行了解下栈原理], 例如: var arr [3]int func updateArr(arr [3]int) { (arr)[0] = 10 // arr[0] = 10 } updateArr(&arr) // 此时 arr 变量的内容为 {10, 0, 0}, 通过指针方式将数组数据修改 长度是数组类型的一部分, 在传递函数参数的时候, 需要考虑数组的长度。 从使用上来说没有什么难度, 在这也就不细说, 我将把重点放在内存原理上。 我们看看上述代码的数组在内存里是怎么存放的 从上面的内存图我们可以看到: 数组变量 arr 的内存地址和 数组下标为0 的内存地址是一样的, 由此分析出 数组的第一个元素内存地址就是数组变量的内存地址, 这个应该不会太难理解, 因为数组的第一个元素标志着该数组的存在。 可以看到这5个元素的内存地址其实是有规律的 元素1 0xc00001a0c0 元素2 0xc00001a0c8 元素3 0xc00001a0d0 元素4 0xc00001a0d8 元素5 0xc00001a0e0 尾数都是 0 和 8, 当尾数到 8 时, 前位数 进1, 比如 c 进 d, 2 进 3 ... 主要原因就是因为 int 类型是 8字节 的。如果数组是其他的数据类型也是一样, 根据不同的数据类型占用的字节数 满字节后进1。 (例如: int8 是占用1个字节, int16 是占用2个字节, string 是占用16个字节, 你可以通过 unsafe.Sizeof(arr) 函数查看字节占用) 如果有第六个元素, 那么它的地址应该是 0xc00001a0e8。 好了, 就先介绍到这。 -
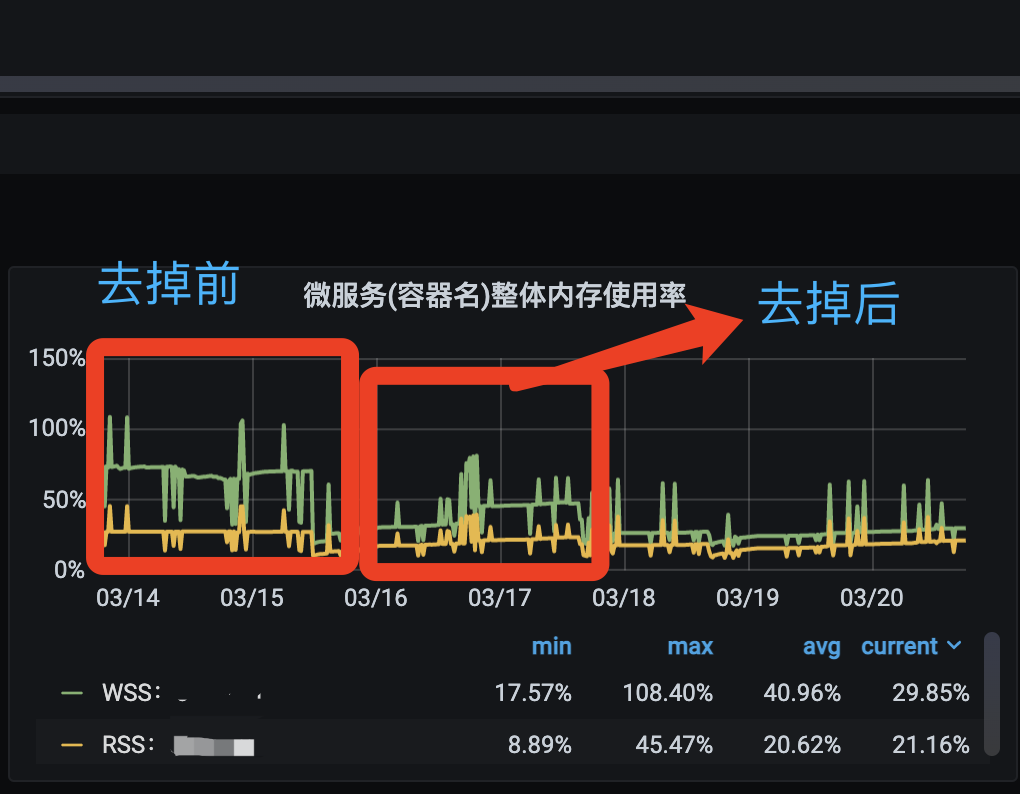
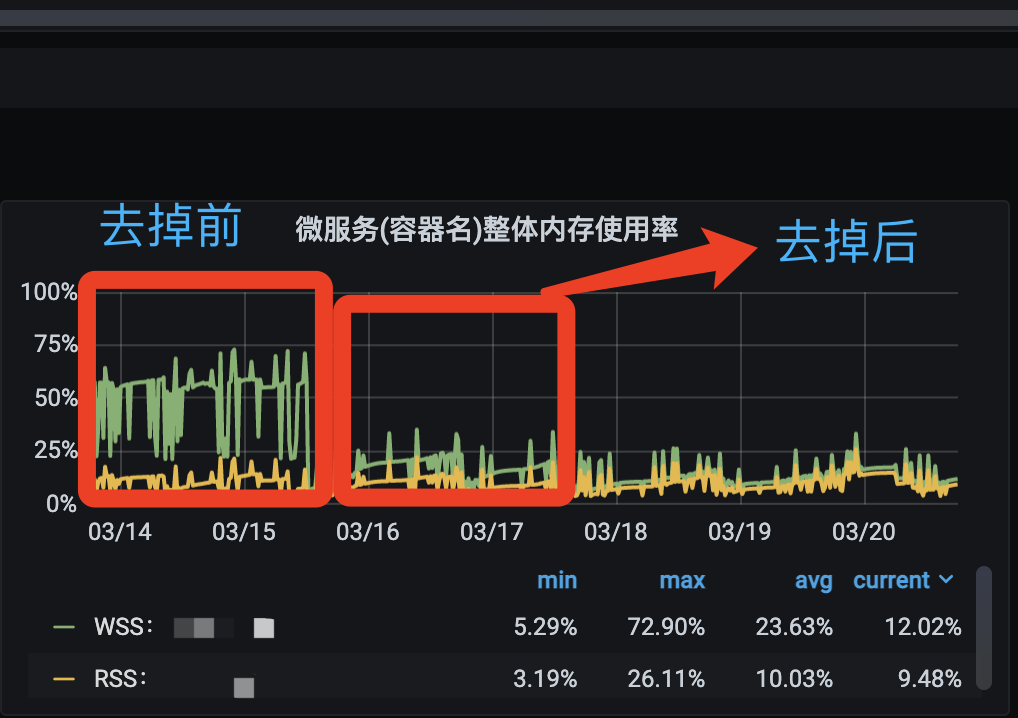
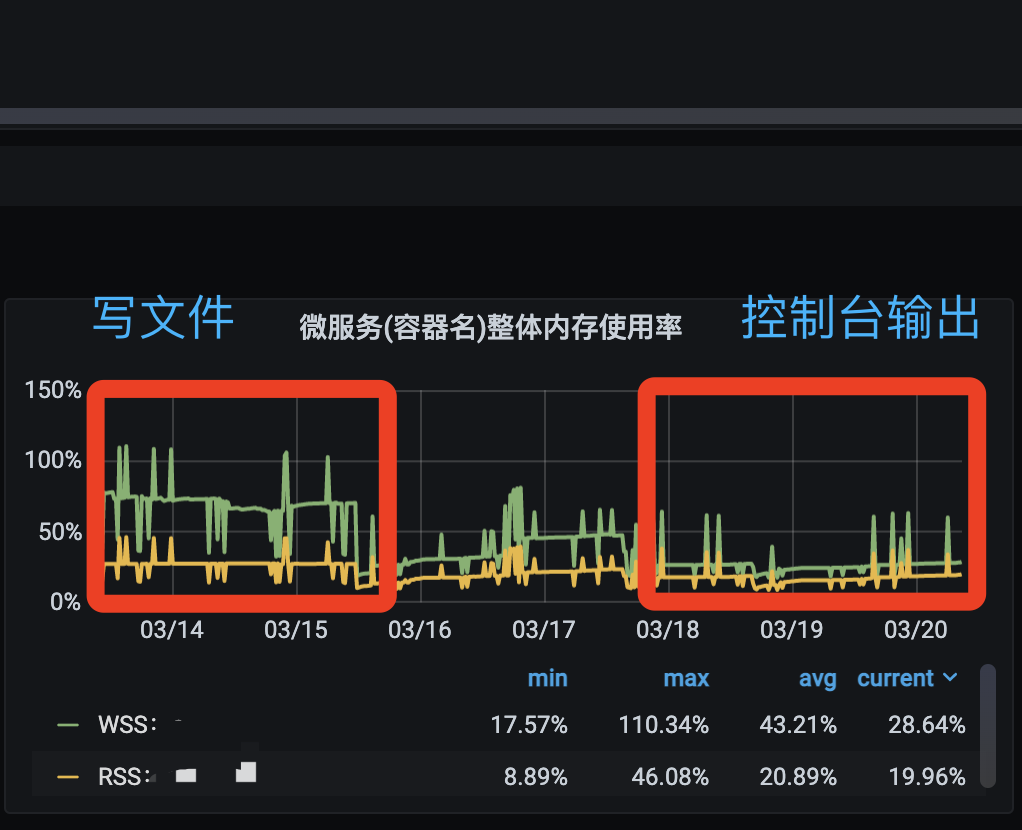
项目内存增大解决方案之日志优化 本文主要实践在 PHP (Swoole 环境) 和 Golang 项目中的 K8S 生产环境解决方案。 内存现象 在部署到 K8S 生产环境 后用 grafana 监控工具发现项目内存很高, 明明业务服务量不算大, 却占用了大量内存。于是排查容器内存情况发现, Buffer Cache 无法释放, 一直在增长。查看代码层也并没有静态变量等现象, 于是我想到每次请求进来都会打印日志, 会不会是不间断地写文件导致文件没法关闭, 内存一直在缓冲区越来越大。为了验证我的猜测, 我尝试把请求日志暂时性关闭, 观察了一天时间发现我的猜测是正确的!内存对比也相对明显(频繁写日志会也明显), 并且容器的总内存也通过自动伸缩机制 降低了2-3个倍数 (因为内存占比是根据总内存大小计算的, 所以内存占比仅仅是反映当前总内存的占用率)!!! 下面是关闭请求日志前后的内存对比: 解决方案 知道了问题就好办了, 解决方案就是: 将日志直接输出到控制台, 运维采集控制台日志到 ELK 。 下面是最终的内存对比: 还在担心服务内存太高 连业务代码都要写的非常小心么? 还在担心写多几行复杂业务 系统炸掉么? 还在担心不敢多打印几个日志? 从此不需要再有此顾虑了!!!
-
