-
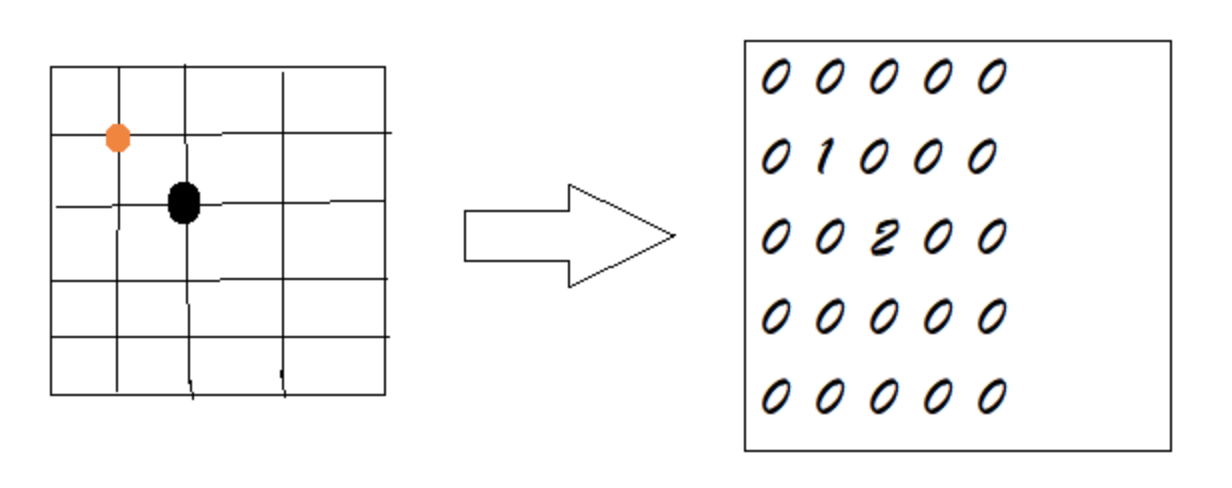
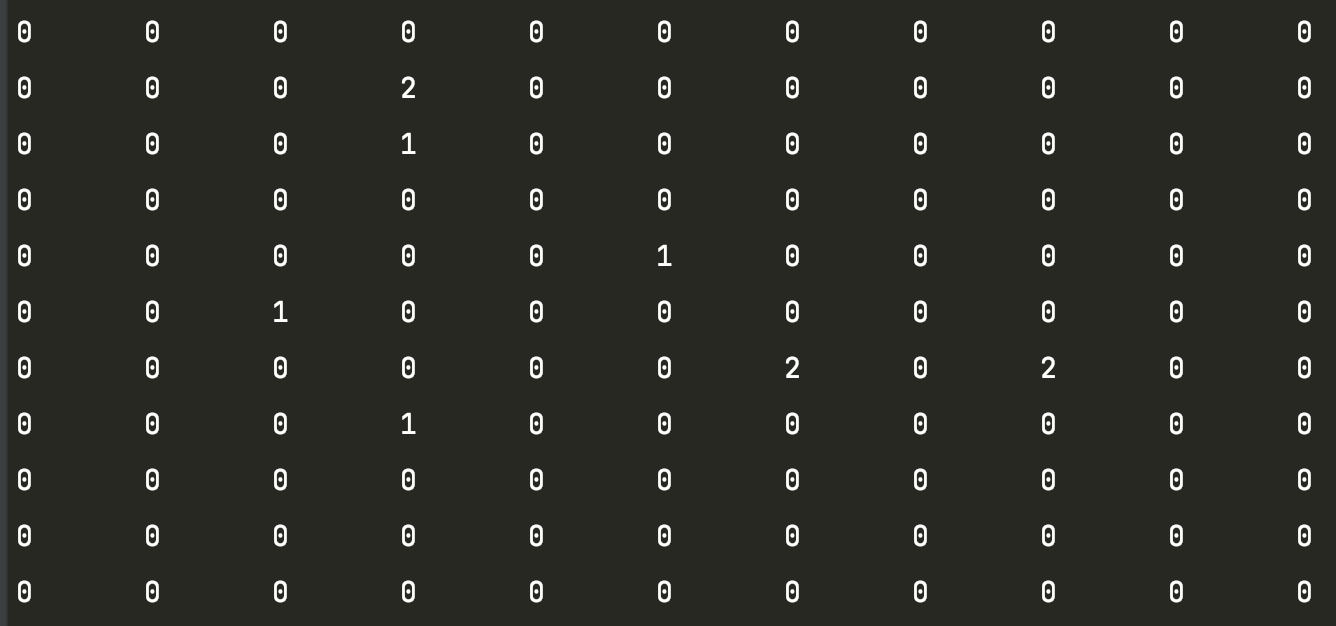
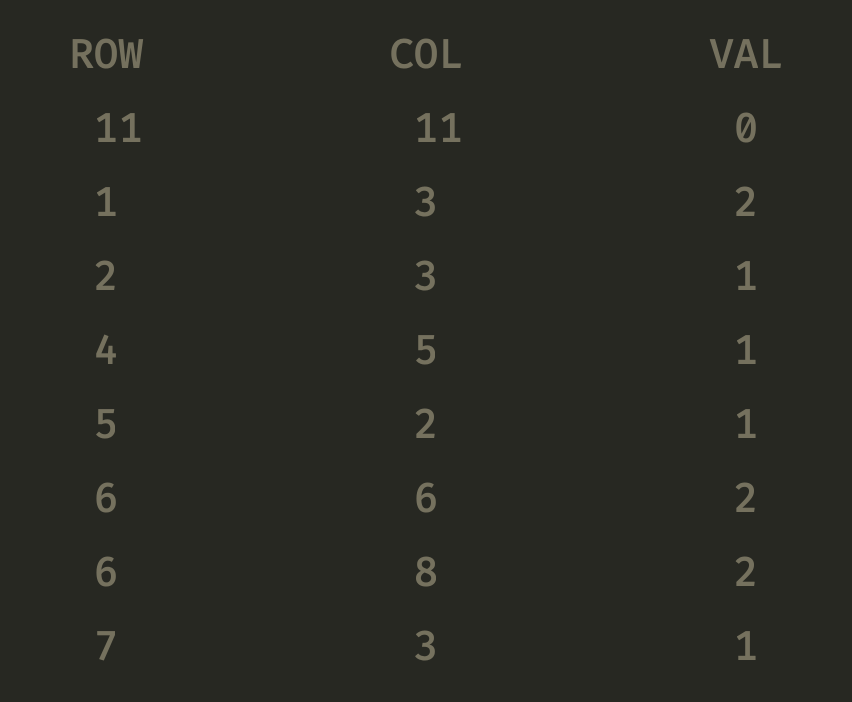
数据结构与算法之稀疏数组 概念 当一个数组中存储了大量为0或者大量相同的数时, 为了缩小程序的规模, 我们可以使用稀疏数组来保存该数组。 处理方式是 通过记录数组一共有几行几列, 有多少个不同的值, 把具有不同值的元素的 行列值 记录在一个小规模数组(稀疏数组)中, 从而缩小程序的规模。 如果不太好理解,这里就举个最经典的五子棋场景。在编写一个五子棋的程序当中,要实现存盘退出和续上盘的功能。如下图所示: 存在一个棋盘, 退出保存的时候应该怎么存储呢? 使用一个二维数组, 1表示红棋, 2表示黑棋, 0表示没有下过的棋。 因为该二维数组的大部分值都是默认的0, 因此记录了很多没有意义的数据, 这个时候就可以使用到 稀疏数组。 实现思路 步骤一 创建二维数组作为源数据, 我们看下源数据效果: 步骤二 遍历原始的二维数组, 将源数据中的有效数据转换为稀疏数组, 并把总行数、总列数和默认值也作为一个元素写入到稀疏数组第一个元素位置。可以看到, 实际有效数据有7个, 但是会产生8个元素, 用来记录总行总列。 步骤三 将稀疏数组复原为源数据, 先单独处理第一行, 创建原始的默认二维数组, 然后再读取稀疏数组中的其他行数据并赋值给二维数组即可。 废话不多说, 直接上代码(Go语言编写) package main import ( "fmt" ) /******* 稀疏数组 - 五子棋案例 *******/ const ( ROW = 11 COL = 11 ) var ( classmap [ROW][COL]int ) type nodeval struct { row int col int val interface{} } func main() { // 输出原始数据 originalData() // 转换为稀疏数组存档 sparsearray := transformationSparseArrayStorage() // 转换为原始数据 transformationOriginalData(sparsearray) } // 原始数据 func originalData() { classmap[1][3] = 2 classmap[2][3] = 1 classmap[5][2] = 1 classmap[6][8] = 2 classmap[7][3] = 1 classmap[4][5] = 1 classmap[6][6] = 2 // 查看数据 for _, v := range classmap { for _, v1 := range v { fmt.Printf("%d\t", v1) } fmt.Println() // 换行输出, 避免影响数据显示 } // 输出: /** 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 */ } // 转换为稀疏数组存档 func transformationSparseArrayStorage() []nodeval { // 转为稀疏数组 (这里使用切片实现) var sparsearray []nodeval // 创建数据模型 sparsearray = append(sparsearray, nodeval{ row: ROW, col: COL, val: 0, }) // 存档 for row, val := range classmap { for col, val1 := range val { if val1 == 0 { continue } // 加入到切片 sparsearray = append(sparsearray, nodeval{ row: row, col: col, val: val1, }) } } fmt.Println(sparsearray) // 此数据可存档入文件、缓存、数据库等, 输出: [{11 11 0} {1 3 2} {2 3 1} {4 5 1} {5 2 1} {6 6 2} {6 8 2} {7 3 1}] return sparsearray } // 转换为原始数据 func transformationOriginalData(sparsearray []nodeval) { var arr [][]int for key, nv := range sparsearray { var v int switch nv.val.(type) { case int: v = nv.val.(int) default: } if key == 0 { // 制作原始表格初始数据 for i := 0; i < nv.row; i++ { var temp []int for j := 0; j < nv.col; j++ { temp = append(temp, v) } arr = append(arr, temp) } // fmt.Println(arr) /** [ [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0 0] ] */ } else { // 棋盘数组内容赋值 arr[nv.row][nv.col] = v } } // 输出数据 for _, v := range arr { for _, v1 := range v { fmt.Printf("%d\t", v1) } fmt.Println() // 换行输出, 避免影响数据显示 } /** 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 */ }
-
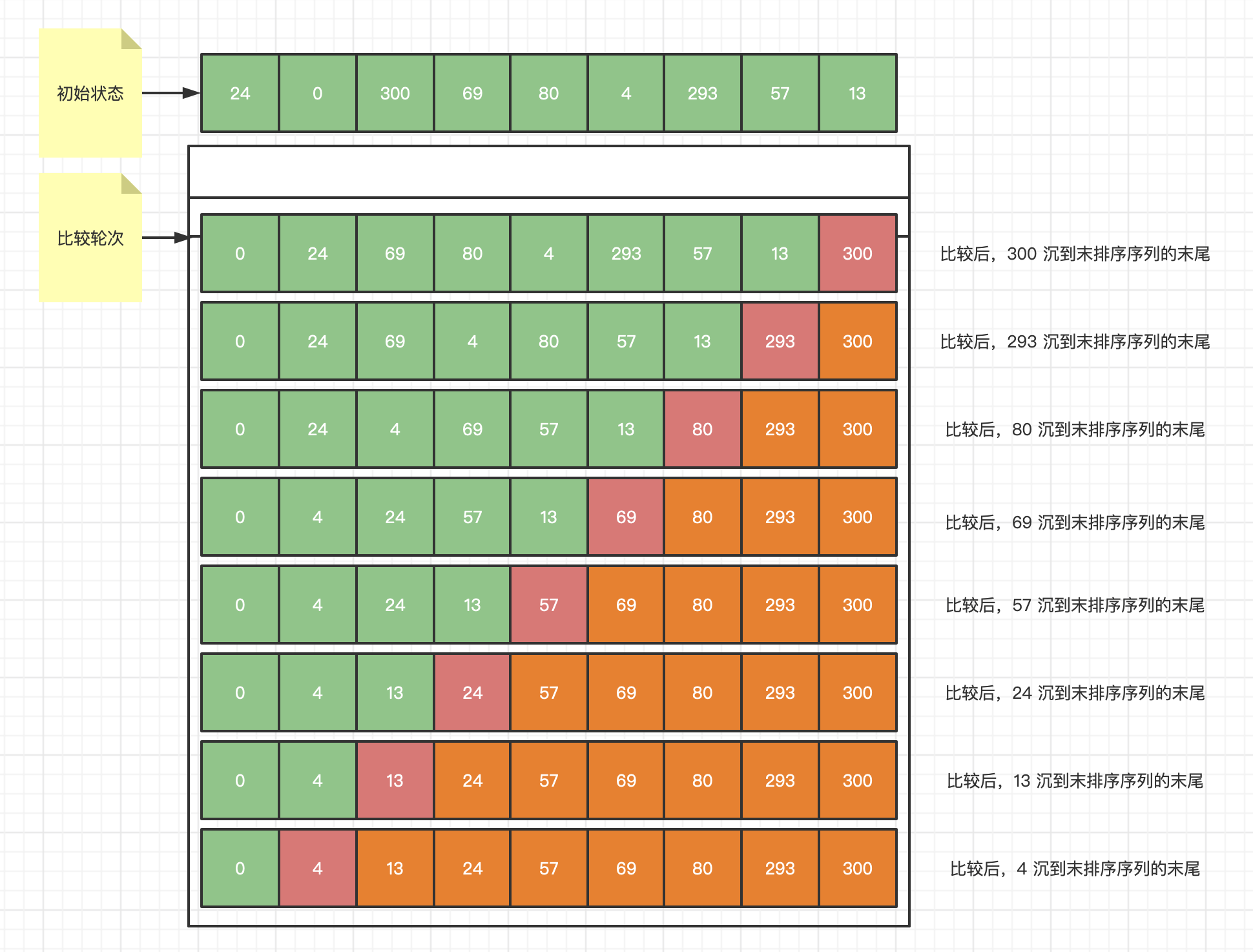 数据结构与算法之冒泡排序 概念 冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。 原理 比较两个相邻的元素,将值大的元素交换到右边。如果遇到相等的值不进行交换,那这种排序方式是稳定的排序方式。 思路 依次比较相邻的两个数,将比较小的数放在前面,比较大的数放在后面 1) 比较第1和第2个数,将小数放在前面,将大数放在后面。 2) 比较第2和第3个数,将小数放在前面,将大数放在后面。 ...依此类推 3) 当比较到第一轮最后两个数时候,将小数放在前面,将大数放在后面;其中最后一个数肯定是整个数组中的最大数,所以在接下来的轮次中是不需要参与比较的。 4) 在上面一轮比较完成后,需要重复如上步骤,每一轮比较次数依次减少,并且每一轮过后都会有一个不需要参与下轮比较的值,直至全部排序完成。 图解冒泡排序 需要参与冒泡排序的数组: [24, 0, 300, 69, 80, 4, 293, 57, 13] 算法分析可以看到: 逻辑处理: N个数字要排序完成,总共进行 N-1 轮次排序,每一次的排序次数为(N-i)次。所以可以用双重循环语句,外层控制循环总轮次,内层控制每一轮的循环次数。 规则原理: 每进行一轮次排序,就会少比较一次,因为每进行一轮排序都会找出一个较大值。如上例: 第一轮比较之后,排在最后的一个数一定是最大的一个数,第二趟排序的时候,只需要比较除了最后一个数以外的其他的数,同样也能找出一个最大的数排在参与第二轮比较的数后面,第三轮比较的时候,只需要比较除了最后两个数以外的其他的数,以此类推…… 也就是说,每进行一轮比较,每一轮少比较一次,一定程度上减少了算法的量。 时间复杂度: (1) 如果我们的数据正序,只需要走一轮即可完成排序。所需的比较次数C和记录移动次数M均达到最小值,即:Cmin=n-1; Mmin=0; 所以,冒泡排序最好的时间复杂度为O(n)。 (2) 如果很不幸我们的数据是反序的,则需要进行n-1轮次排序。每轮次排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值。 冒泡排序总的平均时间复杂度为:O(n^2) [n的平方] , 时间复杂度和数据状况无关。 接下来用 Go 实现冒泡排序算法代码 package main import "fmt" /******* 冒泡排序法 *******/ func main() { var arr = [9]int{24, 0, 300, 69, 80, 4, 293, 57, 13} for j := 0; j < len(arr) - 1; j++ { var oldArr = arr var nextTotalLen = len(arr) - j - 1 for i := 0; i < len(arr); i++ { if i < nextTotalLen { var nextKey = i + 1 if arr[i] > arr[nextKey] { // 前面值大于后面值时, 位置置换 var nextVal = arr[i] arr[i] = arr[nextKey] arr[nextKey] = nextVal } } } // 值完全相同则不需要继续循环下去了 if oldArr == arr { break } } fmt.Println(arr) /** 输出: [0 4 13 24 57 69 80 293 300] */ }
数据结构与算法之冒泡排序 概念 冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。 原理 比较两个相邻的元素,将值大的元素交换到右边。如果遇到相等的值不进行交换,那这种排序方式是稳定的排序方式。 思路 依次比较相邻的两个数,将比较小的数放在前面,比较大的数放在后面 1) 比较第1和第2个数,将小数放在前面,将大数放在后面。 2) 比较第2和第3个数,将小数放在前面,将大数放在后面。 ...依此类推 3) 当比较到第一轮最后两个数时候,将小数放在前面,将大数放在后面;其中最后一个数肯定是整个数组中的最大数,所以在接下来的轮次中是不需要参与比较的。 4) 在上面一轮比较完成后,需要重复如上步骤,每一轮比较次数依次减少,并且每一轮过后都会有一个不需要参与下轮比较的值,直至全部排序完成。 图解冒泡排序 需要参与冒泡排序的数组: [24, 0, 300, 69, 80, 4, 293, 57, 13] 算法分析可以看到: 逻辑处理: N个数字要排序完成,总共进行 N-1 轮次排序,每一次的排序次数为(N-i)次。所以可以用双重循环语句,外层控制循环总轮次,内层控制每一轮的循环次数。 规则原理: 每进行一轮次排序,就会少比较一次,因为每进行一轮排序都会找出一个较大值。如上例: 第一轮比较之后,排在最后的一个数一定是最大的一个数,第二趟排序的时候,只需要比较除了最后一个数以外的其他的数,同样也能找出一个最大的数排在参与第二轮比较的数后面,第三轮比较的时候,只需要比较除了最后两个数以外的其他的数,以此类推…… 也就是说,每进行一轮比较,每一轮少比较一次,一定程度上减少了算法的量。 时间复杂度: (1) 如果我们的数据正序,只需要走一轮即可完成排序。所需的比较次数C和记录移动次数M均达到最小值,即:Cmin=n-1; Mmin=0; 所以,冒泡排序最好的时间复杂度为O(n)。 (2) 如果很不幸我们的数据是反序的,则需要进行n-1轮次排序。每轮次排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值。 冒泡排序总的平均时间复杂度为:O(n^2) [n的平方] , 时间复杂度和数据状况无关。 接下来用 Go 实现冒泡排序算法代码 package main import "fmt" /******* 冒泡排序法 *******/ func main() { var arr = [9]int{24, 0, 300, 69, 80, 4, 293, 57, 13} for j := 0; j < len(arr) - 1; j++ { var oldArr = arr var nextTotalLen = len(arr) - j - 1 for i := 0; i < len(arr); i++ { if i < nextTotalLen { var nextKey = i + 1 if arr[i] > arr[nextKey] { // 前面值大于后面值时, 位置置换 var nextVal = arr[i] arr[i] = arr[nextKey] arr[nextKey] = nextVal } } } // 值完全相同则不需要继续循环下去了 if oldArr == arr { break } } fmt.Println(arr) /** 输出: [0 4 13 24 57 69 80 293 300] */ } -
 聊聊 MySQL 索引数据结构 前言 当你遇到了一条慢 SQL 需要进行优化时,你第一时间能想到的优化手段是什么? 大部分人第一反应可能都是添加索引,在大多数情况下面,索引能够将一条 SQL 语句的查询效率提高几个数量级。 索引的本质:用于快速查找记录的一种 数据结构 索引的常用数据结构: 二叉树 红黑树 Hash 表 B-TREE (B树,并不叫什么B减树) B+TREE 数据结构图形化: 点击查阅 索引数据结构 大家知道 SELECT * FROM t WHERE col = 88 这么一条 SQL 语句如果不走索引进行查找的话,正常地查就是全表扫描:从表的第一行记录开始逐行找,把每一行的 col 字段的值和 88 进行对比,这明显效率是很低的。 而如果走索引的话,查询的流程就完全不一样了(假设现在用一棵平衡二叉树数据结构存储我们的索引列) 此时该二叉树的存储结构(Key - Value):Key 就是索引字段的数据,Value 就是索引所在行的磁盘文件地址。 当最后找到了 88 的时候,就可以把它的 Value 对应的磁盘文件地址拿出来,然后就直接去磁盘上去找这一行的数据,这时候的速度就会比全表扫描要快很多。 但实际上 MySQL 底层并没有用二叉树来存储索引数据,是用的 B+TREE(B+树) 为什么不采用二叉树 假设此时用普通二叉树记录 id 索引列,我们在每插入一行记录的同时还要维护二叉树索引字段 此时找 id = 7 这一行记录时找了 6 次,和我们全表扫描也没什么很大区别。显而易见,二叉树对于这种依次递增的数据列其实是不适合作为索引的数据结构。 为什么不采用 Hash 表 Hash 表:一个快速搜索的数据结构,搜索的时间复杂度 O(1) Hash 函数:将一个任意类型的 key,可以转换成一个 int 类型的下标 假设此时用 Hash 表记录 id 索引列,我们在每插入一行记录的同时还要维护 Hash 表索引字段。 这时候开始查找 id = 7 的树节点仅找了 1 次,效率非常高了。 但 MySQL 的索引依然不采用能够精准定位的Hash 表。因为它不适用于范围查询 为什么不采用红黑树 红黑树 是一种特化的 AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡;若一棵二叉查找树是红黑树,则它的任一子树必为红黑树。 假设此时用红黑树记录 id 索引列,我们在每插入一行记录的同时还要维护红黑树索引字段。 插入过程中会发现它与普通二叉树不同的是当一棵树的左右子树高度差 > 1 时,它会进行自旋操作,保持树的平衡。 这时候开始查找 id = 7 的树节点只找了 3 次,比所谓的普通二叉树还是要更快的。 但 MySQL 的索引依然不采用能够精确定位和范围查询都优秀的红黑树。 因为当 MySQL 数据量很大的时候,索引的体积也会很大,可能内存放不下,所以需要从磁盘上进行相关读写,如果树的层级太高,则读写磁盘的次数(I/O交互)就会越多,性能就会越差。 红黑树 目前的唯一不足点就是树的高度不可控,所以现在我们的切入点就是树的高度。 目前一个节点是只分配了一个存储 1 个元素,如果要控制高度,我们就可以把一个节点分配的空间更大一点,让它横向存储多个元素,这个时候高度就可控了。这么个改造过程,就变成了 B-TREE B-TREE 和 B+TREE BTREE 是一颗多路平衡查找树 定义如下 每个节点最多有m-1个关键字(可以存有的键值对) 根节点最少可以只有1个关键字 非根节点至少有m/2个关键字 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同 每个节点都存有索引和数据,也就是对应的 Key 和 Value 根节点的关键字数量范围:1 <= k <= m-1,非根节点的关键字数量范围:m/2 <= k <= m-1 B-TREE 的查找其实和二叉树很相似 二叉树是每个节点上有一个关键字和两个分支,B-TREE 上每个节点有 k 个关键字和 (k + 1) 个分支。 二叉树的查找只考虑向左还是向右走,而 B-TREE 中需要由多个分支决定。 B-TREE 的查找分两步 首先查找节点,由于 B-TREE 通常是在磁盘上存储的所以这步需要进行磁盘IO操作 查找关键字,当找到某个节点后将该节点读入内存中然后通过顺序或者折半查找来查找关键字。若没有找到关键字,则需要判断大小来找到合适的分支继续查找 B-TREE 和 B+TREE 的相同点 根节点至少一个元素, 根节点至少有两个节点 每个中间节点都包含k-1个元素和k个孩子,其中m/2<=k<=m 每一个叶子节点都包含k-1个元素,其中m/2<=k<=m 所有的叶子节点都位于同一层 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分 B+TREE 是 BTREE 的变种, 拥有新特性 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点 所有的叶子节点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素 B+TREE 比 BTREE 的优势 单一节点存储更多的元素,使得查询的IO次数减少 所有查询都要查找到叶子节点,查询性能稳定 所有叶子节点形成有序链表,便于范围查询 我们具体来看一下B+树结构 我们可以直观地看出节点之间含有重复元素,叶子节点还用指针连在了一起,注意: 叶子节点其实还是个双向指针, 图中未体现右到左的指针而已。每个父节点中的元素都出现在了子节点中,是子节点中的最大(或最小)元素 如上图,根节点中元素8是子节点2,5,8的最大元素,也是叶子节点6,8的最大元素,根节点元素15是子节点11,15的最大元素,也是叶子节点13,15的最大元素。需要注意的是,根节点的最大元素(此处是15)等同于整个B+树的最大元素。无论插入或删除多少元素,始终要保持最大元素在根节点当中。至于叶子节点,由于父节点的元素都出现在了子节点,所以叶子节点包含了全部元素信息。并且每个叶子节点都带有指向下一个节点的指针,形成了一个有序链表 B+树还有一个至关重要的特点,那就是”卫星数据“的位置,所谓 ”卫星数据“,指的是索引元素所指向的数据记录(比如数据库中的某一行) 在B树中,无论中间节点还是叶子节点都带有卫星数据 而在B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联 在数据库的聚集索引中,叶子节点直接包含卫星数据,在非聚集索引中,叶子节点带有指向卫星数据的指针 B+树被设计如此,优势主要体现在查询性能上 单元素查询的时候,B+树会自顶向下逐层查找节点,最终找到匹配的叶子节点,比如我们查找元素3 由此看来,B树的范围查询确实有点繁琐,反观B+树的范围查询则简单的多,只需在链表上做遍历即可 如此看来B+树的链表遍历要比B树的中序遍历简单很多
聊聊 MySQL 索引数据结构 前言 当你遇到了一条慢 SQL 需要进行优化时,你第一时间能想到的优化手段是什么? 大部分人第一反应可能都是添加索引,在大多数情况下面,索引能够将一条 SQL 语句的查询效率提高几个数量级。 索引的本质:用于快速查找记录的一种 数据结构 索引的常用数据结构: 二叉树 红黑树 Hash 表 B-TREE (B树,并不叫什么B减树) B+TREE 数据结构图形化: 点击查阅 索引数据结构 大家知道 SELECT * FROM t WHERE col = 88 这么一条 SQL 语句如果不走索引进行查找的话,正常地查就是全表扫描:从表的第一行记录开始逐行找,把每一行的 col 字段的值和 88 进行对比,这明显效率是很低的。 而如果走索引的话,查询的流程就完全不一样了(假设现在用一棵平衡二叉树数据结构存储我们的索引列) 此时该二叉树的存储结构(Key - Value):Key 就是索引字段的数据,Value 就是索引所在行的磁盘文件地址。 当最后找到了 88 的时候,就可以把它的 Value 对应的磁盘文件地址拿出来,然后就直接去磁盘上去找这一行的数据,这时候的速度就会比全表扫描要快很多。 但实际上 MySQL 底层并没有用二叉树来存储索引数据,是用的 B+TREE(B+树) 为什么不采用二叉树 假设此时用普通二叉树记录 id 索引列,我们在每插入一行记录的同时还要维护二叉树索引字段 此时找 id = 7 这一行记录时找了 6 次,和我们全表扫描也没什么很大区别。显而易见,二叉树对于这种依次递增的数据列其实是不适合作为索引的数据结构。 为什么不采用 Hash 表 Hash 表:一个快速搜索的数据结构,搜索的时间复杂度 O(1) Hash 函数:将一个任意类型的 key,可以转换成一个 int 类型的下标 假设此时用 Hash 表记录 id 索引列,我们在每插入一行记录的同时还要维护 Hash 表索引字段。 这时候开始查找 id = 7 的树节点仅找了 1 次,效率非常高了。 但 MySQL 的索引依然不采用能够精准定位的Hash 表。因为它不适用于范围查询 为什么不采用红黑树 红黑树 是一种特化的 AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡;若一棵二叉查找树是红黑树,则它的任一子树必为红黑树。 假设此时用红黑树记录 id 索引列,我们在每插入一行记录的同时还要维护红黑树索引字段。 插入过程中会发现它与普通二叉树不同的是当一棵树的左右子树高度差 > 1 时,它会进行自旋操作,保持树的平衡。 这时候开始查找 id = 7 的树节点只找了 3 次,比所谓的普通二叉树还是要更快的。 但 MySQL 的索引依然不采用能够精确定位和范围查询都优秀的红黑树。 因为当 MySQL 数据量很大的时候,索引的体积也会很大,可能内存放不下,所以需要从磁盘上进行相关读写,如果树的层级太高,则读写磁盘的次数(I/O交互)就会越多,性能就会越差。 红黑树 目前的唯一不足点就是树的高度不可控,所以现在我们的切入点就是树的高度。 目前一个节点是只分配了一个存储 1 个元素,如果要控制高度,我们就可以把一个节点分配的空间更大一点,让它横向存储多个元素,这个时候高度就可控了。这么个改造过程,就变成了 B-TREE B-TREE 和 B+TREE BTREE 是一颗多路平衡查找树 定义如下 每个节点最多有m-1个关键字(可以存有的键值对) 根节点最少可以只有1个关键字 非根节点至少有m/2个关键字 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同 每个节点都存有索引和数据,也就是对应的 Key 和 Value 根节点的关键字数量范围:1 <= k <= m-1,非根节点的关键字数量范围:m/2 <= k <= m-1 B-TREE 的查找其实和二叉树很相似 二叉树是每个节点上有一个关键字和两个分支,B-TREE 上每个节点有 k 个关键字和 (k + 1) 个分支。 二叉树的查找只考虑向左还是向右走,而 B-TREE 中需要由多个分支决定。 B-TREE 的查找分两步 首先查找节点,由于 B-TREE 通常是在磁盘上存储的所以这步需要进行磁盘IO操作 查找关键字,当找到某个节点后将该节点读入内存中然后通过顺序或者折半查找来查找关键字。若没有找到关键字,则需要判断大小来找到合适的分支继续查找 B-TREE 和 B+TREE 的相同点 根节点至少一个元素, 根节点至少有两个节点 每个中间节点都包含k-1个元素和k个孩子,其中m/2<=k<=m 每一个叶子节点都包含k-1个元素,其中m/2<=k<=m 所有的叶子节点都位于同一层 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分 B+TREE 是 BTREE 的变种, 拥有新特性 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点 所有的叶子节点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素 B+TREE 比 BTREE 的优势 单一节点存储更多的元素,使得查询的IO次数减少 所有查询都要查找到叶子节点,查询性能稳定 所有叶子节点形成有序链表,便于范围查询 我们具体来看一下B+树结构 我们可以直观地看出节点之间含有重复元素,叶子节点还用指针连在了一起,注意: 叶子节点其实还是个双向指针, 图中未体现右到左的指针而已。每个父节点中的元素都出现在了子节点中,是子节点中的最大(或最小)元素 如上图,根节点中元素8是子节点2,5,8的最大元素,也是叶子节点6,8的最大元素,根节点元素15是子节点11,15的最大元素,也是叶子节点13,15的最大元素。需要注意的是,根节点的最大元素(此处是15)等同于整个B+树的最大元素。无论插入或删除多少元素,始终要保持最大元素在根节点当中。至于叶子节点,由于父节点的元素都出现在了子节点,所以叶子节点包含了全部元素信息。并且每个叶子节点都带有指向下一个节点的指针,形成了一个有序链表 B+树还有一个至关重要的特点,那就是”卫星数据“的位置,所谓 ”卫星数据“,指的是索引元素所指向的数据记录(比如数据库中的某一行) 在B树中,无论中间节点还是叶子节点都带有卫星数据 而在B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联 在数据库的聚集索引中,叶子节点直接包含卫星数据,在非聚集索引中,叶子节点带有指向卫星数据的指针 B+树被设计如此,优势主要体现在查询性能上 单元素查询的时候,B+树会自顶向下逐层查找节点,最终找到匹配的叶子节点,比如我们查找元素3 由此看来,B树的范围查询确实有点繁琐,反观B+树的范围查询则简单的多,只需在链表上做遍历即可 如此看来B+树的链表遍历要比B树的中序遍历简单很多